

Data Science Roadmap 2026
And why it still matters today!!!


Hi, I’m Shirin Khosravi Jam, and before I ever touched LLMs, GPUs, Docker, or AWS, I was just someone with a mathematics background trying to figure out how to break into DS/ML.
My journey didn’t start with any models. It started with Python scripts, SQL queries, Pandas dataframes, a lot of data cleaning and a lot of debugging.
For the first five years of my career, I worked extensively on classical Data Science: statistics, forecasting, regression models, experimentation, dashboards, recommendation systems, marketing optimization.
Only later did I move into modern AI systems: RAG pipelines, AI Agents, LLM-powered customer support assistants, and production-grade MLOps running inside a regulated fintech environment. Along the way, I learned the part nobody warns you about: most of the real work is data, pipelines, debugging, deployment, and monitoring, not training neural nets every now and then.
Today I build and ship AI systems that actually move business metrics, and I teach the same to others through Jam with AI. But I didn’t get here by chasing trends. I got here by layering skills, slowly, deliberately, and in the right order.
This roadmap is the version I wish someone had handed me years ago. It’s not theory. It’s the path I myself walked and still walking, compressed and rearranged for someone starting now. If you are serious, consistent, and willing to build, this is enough to go from:
“I can write Python” → to “I can ship ML systems that generate value.”
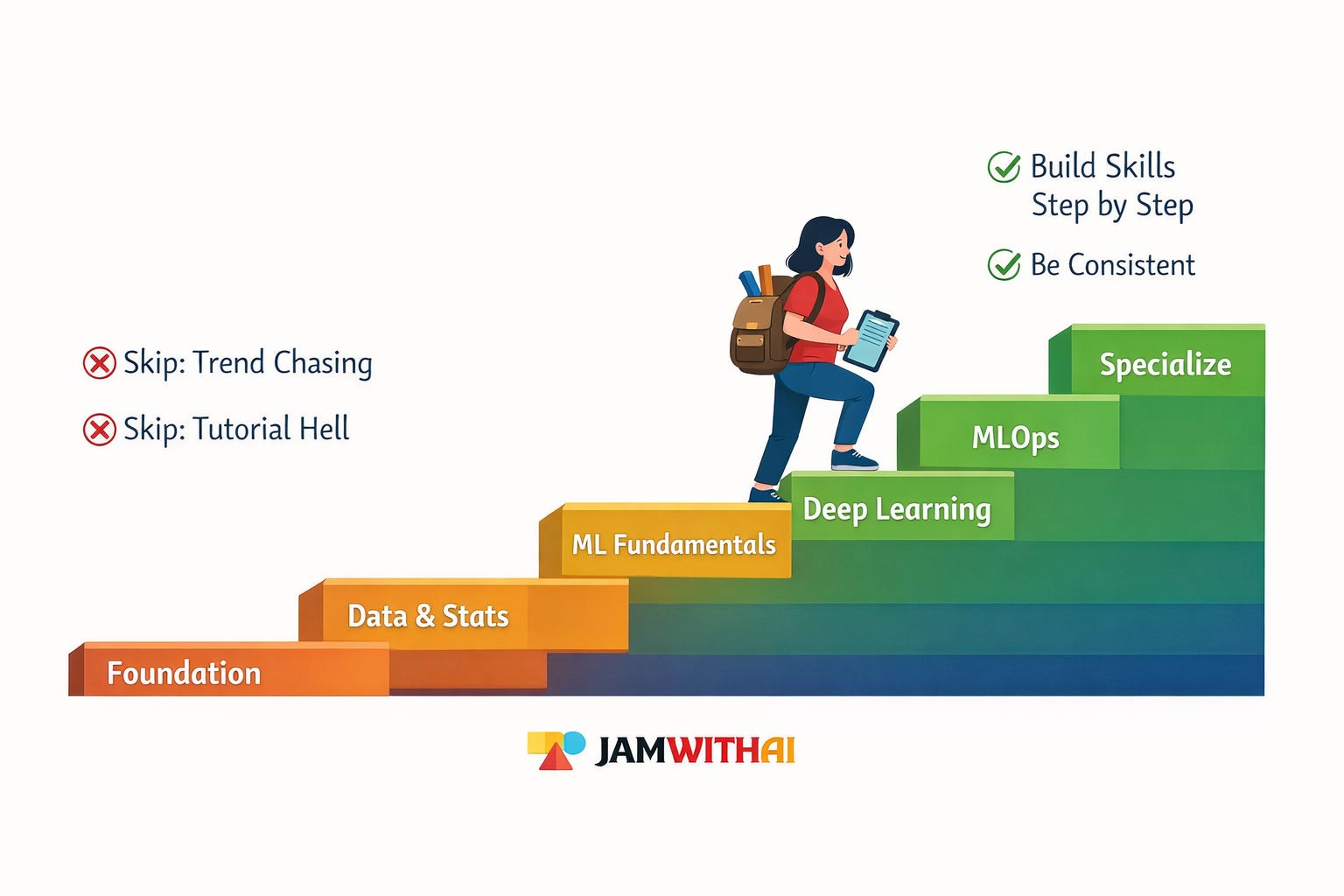
Now let’s start at the beginning: Phase 0.
You can watch the below video walkthrough:
Phase 0: Foundation & Programming (2 months)
“Before you build ML models, learn to build software”
Essential Skills:
Python fundamentals: Variables, data structures, functions, OOP
Version control: Git & GitHub (branching, commits, pull requests)
Command line basics: Navigate, create scripts, environment management
SQL: Queries, joins, aggregations, window functions
AI coding assistant: Claude/Cursor (get comfortable with using AI tools)
SKIP:
❌ Skip: Advanced Python design patterns initially, you’ll learn them when needed
❌ Skip: Multiple programming languages (R, Scala), Python is enough to start
Milestone Projects:
Build a data pipeline: Scrape data from an API → Clean it → Store in SQLite → Query insights
GitHub portfolio setup: Create at least 1 repo and add your first python logic with proper README file
Timeline Checkpoint:
✅ Can write Python scripts
✅ Comfortable with Git workflow
✅ Can query databases and manipulate data
Resources:
Video series: CS50's Introduction to Programming with Python (Harvard)
Python Course by DataCamp - https://datacamp.pxf.io/5k5gab
SQL Course by DataCamp - https://datacamp.pxf.io/zzxae6
Practice: HackerRank - Python basics track
Phase 1: Data Analysis & Statistics (2 months)
“Learn to ask the right questions before building models”
Essential Skills:
Pandas & NumPy: Data manipulation, filtering, grouping, merging
Data visualization: Matplotlib, Seaborn (build graphs and tell stories with data)
Statistics foundations: Distributions, hypothesis testing, correlation vs causation
Exploratory Data Analysis (EDA): Finding patterns, handling missing data, outliers
SKIP:
❌ Skip: Deep statistical theory, focus more on practical application
❌ Skip: Advanced visualization tools (Tableau, Power BI), start with Python viz
Milestone Projects:
End-to-end analysis:
Take a Kaggle dataset → Ask 5 business questions → Answer with visualizationsA/B test analysis:
Design and analyze a hypothetical A/B test (document assumptions, calculate sample size, interpret results)Data quality report:
Build a reusable script that profiles any dataset (missing values, distributions, correlations)
Timeline Checkpoint:
✅ Can perform EDA independently
✅ Know when correlation ≠ causation
✅ Can communicate insights to non-technical stakeholders
Resources:
Data analytics Track by DataCamp - https://datacamp.pxf.io/OYeRmn
Practice data: Kaggle Datasets, e.g. House Prices Dataset
Phase 2: Machine Learning Fundamentals (2 months)
“Understand the math, but focus on when to use what”
Essential Skills:
Supervised learning: Linear/Logistic Regression, Decision Trees, Random Forests, Gradient Boosting (XGBoost, LightGBM)
Unsupervised learning: K-means, hierarchical clustering, PCA
Model evaluation: Train/test split, cross-validation, metrics (precision, recall, F1, RMSE, MAE)
Feature engineering: Creating, selecting, and transforming features
Scikit-learn mastery: Pipelines, transformers, model selection
SKIP:
❌ Skip: Deep mathematical proofs, understand concepts, not derivations
❌ Skip: Implementing algorithms from scratch (unless interviewing at FAANG)
❌ Skip: AutoML tools, learn manual process first
Milestone Projects:
Regression project: Predict house prices or sales → Feature engineering → Model comparison → Error analysis
Classification project: Customer churn prediction → Handle imbalanced data → Choose right metrics
Clustering analysis: Customer segmentation → Determine optimal K → Interpret business value of segments
Kaggle competition: Participate (don’t aim to win, aim to learn from top solutions)
Timeline Checkpoint:
✅ Can select appropriate algorithm for a problem
✅ Understand bias-variance tradeoff
✅ Can explain model performance to stakeholders
Resources:
Video series: Machine Learning Specialisation by Andrew NG
3blue1brown - Math explanation and animations
Books: Introduction to Statistical Learning (ISLR) - With Python labs, Hands-On Machine Learning by Aurélien Géron
Phase 3: Advanced ML & Deep Learning (2 months)
“Go deep where it matters for your goals”
Essential Skills:
Neural networks basics: Perceptrons, back-propagation, activation functions
Deep learning frameworks: PyTorch OR TensorFlow (pick one, not both initially)
NLP fundamentals: Text preprocessing, embeddings, transformers basics
Time series: ARIMA, Prophet, LSTM for sequential data
LLM basics: Understanding LLM capabilities and limitations
SKIP:
❌ Skip: Building transformers from scratch, use Hugging Face
❌ Skip: Reinforcement learning (unless specific use case)
❌ Skip: Training large models from scratch
Milestone Projects:
NLP project:
Sentiment analysis or text classification → Use pre-trained embeddingsTime series forecasting:
Sales/demand prediction → Compare traditional vs DL approachesLLM application:
Build a RAG system or use OpenAI API for a practical use case
Timeline Checkpoint:
✅ Comfortable with one deep learning framework
✅ Understand and can explain LLM basics
✅ Know when deep learning is overkill
Resources:
Video series: Deep Learning Specialisation by Andrew Ng
Hands-on: Practical deep learning for coders
Video series: Stanford CS224n (NLP)- Youtube
Basic RAG: Build a local RAG system
Phase 4: MLOps & Production ML (3 months)
“This is where real data science happens - and where most tutorials stop”
Essential Skills:
Experiment tracking: MLflow, Weights & Biases
Model deployment: FastAPI, Docker, REST APIs
Cloud basics: AWS (SageMaker, S3, EC2) OR Google Cloud OR Azure (pick one)
Monitoring: Data drift detection, model performance monitoring
CI/CD for ML: GitHub Actions, automated testing
Model serving: Batch vs real-time inference
SKIP:
❌ Skip: Kubernetes (overkill for many projects, start with Docker)
❌ Skip: Building custom ML platforms, use existing tools
Milestone Projects:
End-to-end ML pipeline:
Train model → Track experiments → Version model → Deploy API → Monitor in “production” (Deploy ML model on AWS SageMaker)Dockerized ML service:
Package model + dependencies → Deploy to cloud → Set up basic monitoring (Create REST API with FastAPI)Data pipeline:
Automate data collection → Processing → Model retraining (can reuse code from Phase 0)
Timeline Checkpoint:
✅ Can deploy a model to production (even if it’s a simple one)
✅ Understand the full ML lifecycle
✅ Can debug production ML issues
Resources:
Video series: Machine learning in production by Andrew Ng
Courses: Taking Python to Production
Course repo: https://madewithml.com/courses/mlops/
Phase 5: Specialized Tracks (2-3 months each)
“Pick based on your interests and job market”
Track A: Modern AI Systems
Essential:
RAG systems architecture
Vector databases (Pinecone, Weaviate, Chroma)
LLM application development
Prompt engineering & optimization
AI agents and tool use
Project: Build a production-ready RAG system or AI agent
Resources:
Track B: Recommender Systems
Essential:
Collaborative filtering
Content-based filtering
Matrix factorization
Neural recommendations
Evaluation metrics (NDCG, MRR)
Project: Build a recommendation engine (movies, products, content)
Resources: Recommender Systems
Track C: Advanced MLOps
Essential:
Feature stores
ML orchestration (Airflow, Prefect)
Advanced monitoring & observability
Model optimization (quantization, pruning)
Infrastructure as Code
Project: Build a complete MLOps platform (mini version)
Track D, E, F: Time series, Marketing, Customer Analytics, etc.
Continuous Learning & Real-World Experience
“Never stop building”
Essential Habits:
Build in public: Share projects on GitHub, write about learnings
Read production ML blogs: Uber, Netflix, Spotify engineering blogs
Join competitions selectively: Kaggle for learning, not just rankings
Contribute to open source: Even documentation helps
Stay updated: Follow key researchers and practitioners (not just influencers)
Common Traps to Avoid:
❌ Tutorial hell: Watching 10 courses but building 0 projects
❌ Certification collecting: Companies want to see what you’ve built
❌ Chasing every new trend: Master fundamentals first
❌ Ignoring software engineering: ML engineers are software engineers who know ML
❌ Only working with clean data: Real data is messy, please embrace it
Total Timeline: 6-12 months
(Assuming 15-20 hours/week of focused work)
Realistic Pace:
Months 0-2: Foundation
Months 2-4: Data Analysis & Statistics
Months 4-6: ML Fundamentals
Months 6-8: Advanced ML & DL
Months 8-11: MLOps
Months 11+: Specialization
The Reality Check:
Most ML problems don’t need deep learning
Most “AI” problems don’t need custom models (APIs exist)
Most production issues are data problems, not model problems
Most of your time will be data cleaning and pipeline building
Getting Hired:
Companies want: Can you deliver value? Can you work in a team? Can you ship?
They don’t want: Perfect accuracy on toy datasets
Your GitHub is your resume - make it count
A Final Note
This roadmap still matters today, and years from now.
Whether you end up calling yourself a Data Scientist, ML Engineer, or AI Engineer, the path underneath is the same. Tools will change. Models will evolve. Buzzwords will rotate every year. But the fundamentals: programming, data thinking, statistics, problem framing, and the ability to ship will always compound.
I have seen this firsthand. I built my career through classical Data Science long before LLMs were mainstream, and those same skills are the reason I can now build and deploy modern AI systems with confidence. Nothing here is wasted effort. Every phase builds leverage for the next one.
If you follow this roadmap with patience and intent, you won’t just learn how to train models, you will learn how to solve real problems, work with real data, and create systems that deliver value in the real world.
Build the foundations well.
Everything else becomes easier.
Now go build 💪
Nice insight!
https://builder.aws.com/content/3Af988zLy1hRACEVFnzVuEeU5rz/aideas-finalist-luminalog-privacy-first-observability