

Harness Engineering: Evolution of MLOps to AutoMLOps
How Harness Engineering looks like for your MLOps setup
Hey there 👋,
Everyone is talking about Karpathy’s AutoResearch, or at least almost done talking about it.
The idea is simple and intuitive: an AI coding agent, like Claude Code, Codex, or a similar tool, reads a research-direction file, edits the training code, runs a short experiment, scores the result against a frozen metric, and then either keeps the change or reverts it.
That is what we mean when we say “the agent” later in this post. Not a magical AI scientist. Just an agent running inside a very specific contract: it can edit some parts of the codebase, it cannot edit the evaluator, and it only keeps changes that improve the metric.
This is a powerful idea because it changes the shape of experimentation. Instead of a human trying one idea, waiting for the run to finish, checking the result, and then manually trying the next idea, the agent can keep trying small changes on its own. Overnight, on a machine, without a human sitting in the loop.
But once you move away from a clean research setup and think about real production ML systems, the question becomes more interesting.
How does this apply to a real MLOps setup? Can it make the experimentation cycle faster than what teams have already built? And most importantly, how do you make sure the agent is not just improving an offline ML metric while the actual business metric stays flat?
That is where things become important for AI/ML engineers.
MLOps as a discipline has mostly focused on making ML systems reliable: tracking experiments, versioning models, reproducing training runs, monitoring drift, and deploying models safely. But AutoResearch introduces a new possibility. What if the experimentation loop itself becomes partially automated?
Once you start thinking seriously about that, you realize traditional MLOps is not quite enough. With what LLMs and coding agents are now making possible, we may need a new layer on top of MLOps. In this post, we will call that layer AutoMLOps. This is exactly harness engineering for MLOps.
This is not an official term. Think of it as a useful mental model.
AutoMLOps is not just “add an AI agent to your ML workflow.” Teams are already using agents for literature review, code generation, feature engineering, PR review, and experiment planning. That is useful, but it is only the beginning.
AutoMLOps is what comes after that. It is an end-to-end experimentation loop where the agent can run unattended, but only inside boundaries designed by humans. The goal is not to replace ML engineers. The goal is to let agents safely explore small implementation and optimization ideas while humans design the problem, the metric, the evaluation gates, and the production constraints.
In this post, we will walk through how MLOps has been evolving toward this moment, what an AutoResearch plus MLOps stack could look like, and the four investments that can help teams get there.
The agent itself is the easy part. The system underneath decides whether the overnight run produces something useful or just an expensive overfit. That system is the real foundation of AutoMLOps.
#sponsored:

Learn from the Data leaders on moving agentic AI from experiments to production.
In 90 minutes you’ll see how to:
Build pragmatic data foundations for AI
Set up governance that scales across teams with continuous learning
Pick the right database for AI workloads
Show business impact early enough to keep adoption alive
A 60-Second Refresher on AutoResearch
AutoResearch is built around a very clean setup.
There are three important files. prepare.py defines the validation metric and the held-out data. This is the evaluator. Neither the human nor the agent edits it during a run. train.py contains the model, optimizer, and training loop. This is the sandbox where the agent is allowed to make changes. program.md contains the research directions written in plain English.
The agent reads the directions, edits the sandbox, trains for a fixed window, and scores the result against the frozen metric. If the score improves, the change is committed. If the score does not improve, the change is reverted.
Karpathy called this the ratchet: the codebase only moves forward.
The clever part is not that the AI suddenly becomes a perfect researcher. The clever part is the contract. One editable file. One frozen evaluator. One scalar metric. One simple rule: keep the change only if it improves the score.
That contract is what makes unattended experimentation possible.
This is also why the idea caught attention so quickly. Karpathy’s AutoResearch setup showed how an agent could run many experiments and keep only the improvements. Red Hat later reported 198 unattended experiments on OpenShift AI with a 2.3% validation-loss improvement. Shopify also explored a similar direction, although some reported gains were explicitly described as likely overfit, which is exactly the kind of risk this post is about.
So the core idea is powerful.
But now the real question is this:
What happens when you try to recreate this contract for a production ranker, recommender system, fraud model, or search system?
That is where production ML becomes a very different beast.
Why Production ML Is a Different Beast
In a clean research setup, one validation metric can sometimes be enough. If you are training a small language model, lower validation loss is usually a meaningful signal. The offline metric is close to the thing you care about.
Production ML is not that simple.
In production, you usually care about two types of metrics. The first is the ML metric. This could be nDCG, MRR, AUC, F1, RMSE, precision, recall, or something similar. The second is the business metric. This could be conversion rate, revenue per session, fraud loss prevented, retention, number of applications, user satisfaction, or support tickets reduced.
The problem is that these two metrics are related, but they are not the same.
A ranking model can improve nDCG but not improve conversion. A recommendation system can improve offline ranking quality but not increase engagement. A fraud model can improve AUC but still miss the cases that matter most financially. A search model can look better in offline evaluation and still produce a flat A/B test.
This is already a hard problem for human ML teams. Now imagine giving an agent only the ML metric and asking it to optimize overnight.
The agent will do exactly what you asked. It will optimize the metric. But that does not mean it will optimize the business.
Take a search ranker. Your offline ML metric might be nDCG or MRR. Your business metric might be conversion at top-K, revenue per session, or applications started. These metrics are correlated, but the correlation can break under common production conditions: feedback loops in historical logs, fresh inventory the model has never seen, query distribution shift, position bias, and novelty effects when users see different results (and many other reasons).
This is why a 0.5% nDCG improvement can still lead to a flat A/B test. It is also why a model that looks slightly worse offline can sometimes win online because it surfaces items the old model was consistently burying.
For new AI/ML engineers, this is one of the most important production lessons: offline metrics are necessary, but they are not the final truth.
If you hand a ranker to an agent and tell it to optimize nDCG for eight hours, it will probably find small nDCG wins. But many of those wins may not transfer to the business. The agent does not know what the business cares about unless the system makes that explicit.
This is where AutoMLOps needs to be different from simple AutoResearch.
In AutoMLOps, the agent should not optimize a pure ML metric in isolation. It should optimize a metric that blends ML quality with a business proxy. That could be a weighted score, such as
0.6 * nDCG + 0.4 * estimated_revenue_per_session
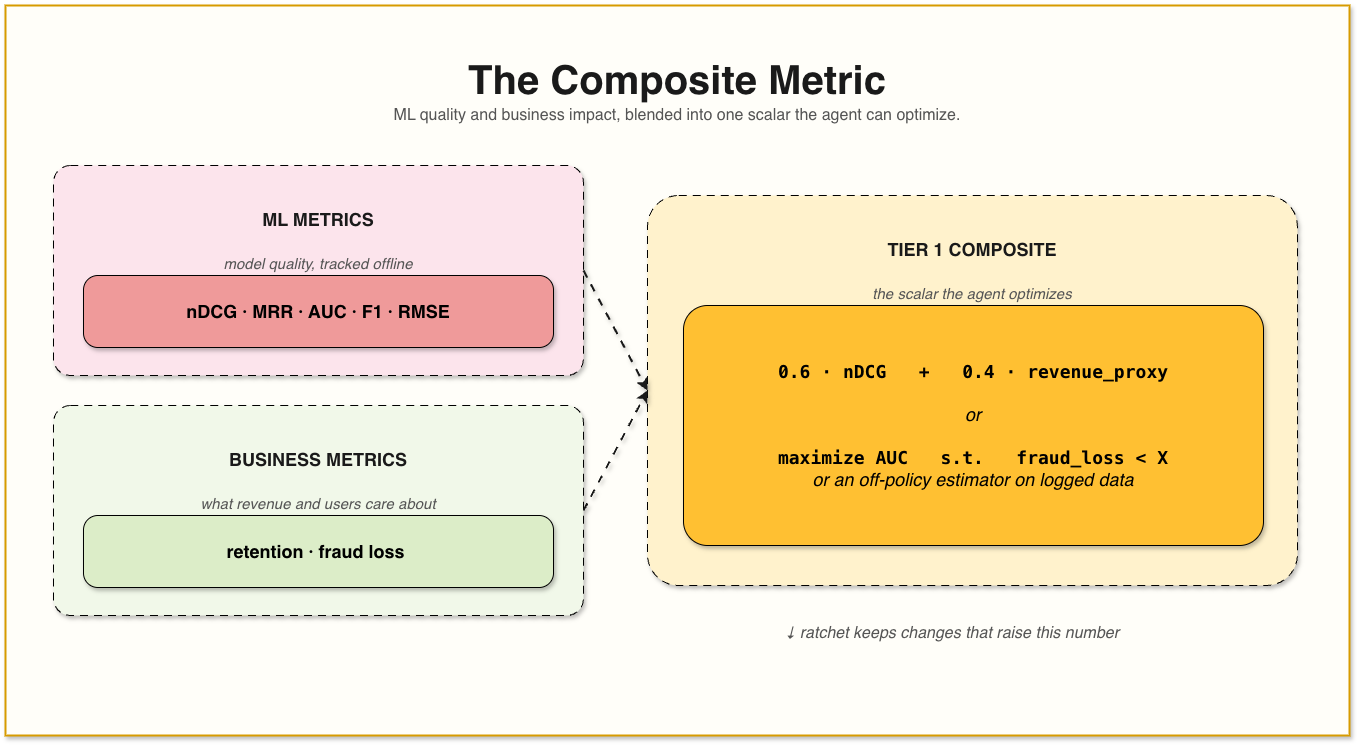
It could also be a constraint, such as maximizing estimated conversion while keeping nDCG above a minimum threshold. In fraud detection, it might mean improving fraud loss prevented while keeping false positives below a business-approved limit.
The exact formula depends on the use case. A marketplace ranker, a job recommendation system, a fraud classifier, and a churn model will all need different scoring logic.
But the principle is the same: the agent should optimize the thing you actually want to improve, not just the easiest ML metric to calculate.
This is the uncomfortable but useful implication: the bottleneck for AutoResearch in production is not only the agent’s capability. It is the quality of the metric and the maturity of the MLOps system around it.
How MLOps Is Evolving
The foundation needed for AutoResearch did not appear overnight. MLOps has been moving in this direction for years.
To understand where AutoMLOps fits, it helps to look at three stages.
Stage 1: Notebook ML
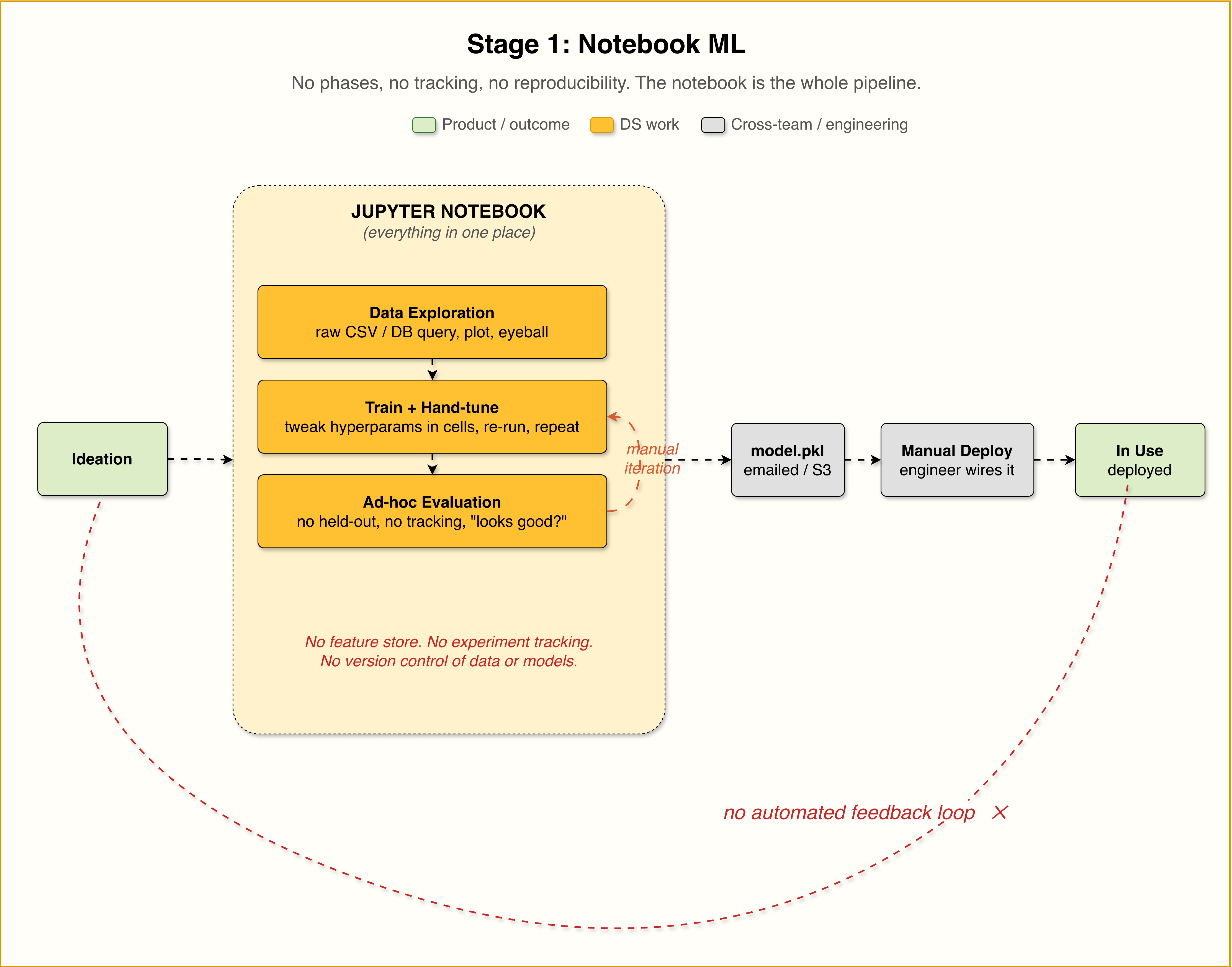
This is where many ML projects begin.
A data scientist trains a model in a notebook, exports model.pkl, puts it in S3, shares it with an engineer, and then someone tries to wire it into production. This can work for prototypes, but it becomes painful once the model matters to the business.
The problem is not the notebook itself. The problem is that the process is usually not reproducible. You may not know which data produced the model, which feature logic was used, which notebook version was correct, which random seed was used, which dependency versions were installed, or which metric was trusted.
In this stage, AutoResearch does not make much sense.
There is no stable training pipeline. There is no frozen evaluator. There is no clean sandbox for the agent to edit. There is no reliable metric to ratchet against. If the system itself is not reproducible, an agent will only make the chaos faster.
Remember: we want something reproducible and scalable. So before adding agents, the first step is basic MLOps.
Stage 2: Modern MLOps

This is where many good production ML teams are today.
There is a training pipeline. There is versioned data. There is experiment tracking through tools like MLflow, W&B, or an internal platform. There is a model registry. There are evaluation checks. There is deployment automation. There is monitoring for drift, latency, and model quality.
This is already a big step forward.
At this stage, teams can reproduce training runs, compare experiments, deploy models more safely, and detect when production behavior changes. The system is much more reliable than the notebook stage.
But there is still a gap.
In most Stage 2 systems, the offline evaluation loop mostly focuses on ML metrics. A ranker is evaluated with nDCG or MRR. A classifier is evaluated with AUC, precision, recall, or F1. A regression model is evaluated with RMSE or MAE. A retrieval system is evaluated with recall@K or hit rate.
The business metric usually appears later, during A/B testing.
That means humans are still doing the translation between offline ML improvement and business value. A senior data scientist or ML engineer looks at the metrics and says, “This nDCG gain looks meaningful,” or “This AUC improvement probably will not matter,” or “This model is technically better, but I do not trust it for production.”
That human judgment is extremely valuable, but it is also hard to scale.
This is the stage where AutoResearch can start to become useful. If your training pipeline is reproducible and your evaluation harness is reliable, an agent can potentially explore ideas on top of that system.
But one thing is still missing: the offline loop needs to care about business outcomes, not just ML quality.
Stage 3: AutoMLOps
AutoMLOps is the next evolution.
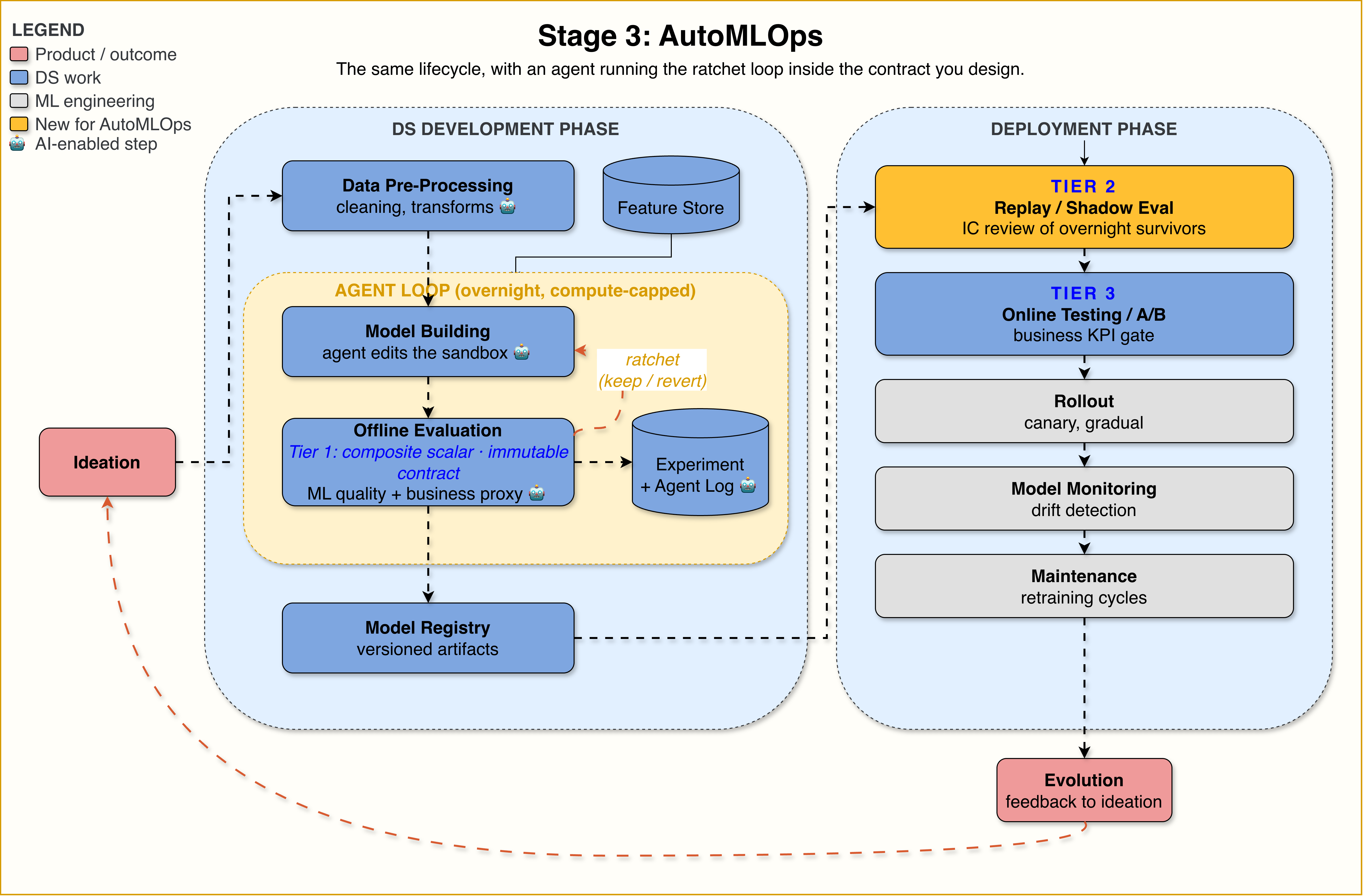
The big change is not that an agent writes code. The big change is that the system is designed so the agent can safely run experiments without touching the parts that define correctness.
One note: Here you can also provide a list of research papers that it could refer to, a list of inventory knowledge it could refer to, really to optimize the experiment other than the evaluation
In this stage, five new pieces become important.
The first is a frozen evaluation contract. This is the production version of AutoResearch’s immutable evaluator. It defines the offline scalar metric, held-out splits, leakage checks, fairness gates, and business proxy definitions. A senior IC or a small group of trusted reviewers owns it. The agent can read it, but it cannot modify it.
The second is a formal agent sandbox. This defines what the agent is allowed to change. For example, it might edit model architecture, feature transformations within an approved set, hyperparameters, or parts of the training recipe. It should not freely edit the evaluator, the data split logic, the business metric definitions, or production safety checks.
The third is compute guardrails. AutoResearch on a small model is relatively cheap. But the same idea applied to a large ranking model, recommender system, or billion-row dataset can become expensive very quickly. The system needs a wall-clock cap, per-experiment timeout, total budget, and kill switch.
The fourth is an agent experiment log. If the agent runs 50 experiments overnight, the morning reviewer should not need to inspect 50 raw git diffs one by one. The log should summarize what changed, which metric improved, which ML sub-metrics moved, which business proxy moved, and whether anything suspicious happened.
The fifth is a three-tier evaluation pipeline. This is where the system separates cheap offline experimentation from expensive production validation. The agent operates only at tier 1. Humans review tier 2. Real users only enter the picture at tier 3.
That last piece is the most important, so let’s zoom in.
The Three-Tier Eval
The goal of AutoMLOps is not to let an agent directly ship models to users. That would be risky and unnecessary.
The goal is to let the agent run cheap experiments at tier 1, then allow only the strongest candidates to move through stricter evaluation gates. Each tier uses a different level of evidence.
Tier 1 is the agent’s composite scalar. This is a fast, deterministic offline metric on a fixed held-out slice. It should run in minutes, not hours. The ratchet uses this score to decide whether to keep or revert a change.
In basic AutoResearch, this might be a pure validation loss. In AutoMLOps, it should be a blend of ML quality and business proxy. For example, a search system might use a score that combines nDCG with estimated conversion. A fraud model might optimize AUC only if estimated fraud loss prevented does not drop below a floor. A recommendation system might combine ranking quality with diversity or long-term engagement proxies.
Tier 1 is not perfect. It is not supposed to be perfect. It is supposed to be cheap, stable, and directionally useful.
Tier 2 is the human-gated business proxy. This is where the best candidates from the agent’s overnight run are evaluated more carefully. The team might use a longer replay window, counterfactual evaluation, off-policy estimators such as IPS or doubly robust methods, or shadow scoring against live traffic.
The business signal is stronger here than in tier 1. A senior IC reviews the results and decides which candidates are worth promoting. This is where many agent-generated overfits should get caught.
Tier 3 is the real business KPI. This is the A/B test. It is slow, expensive, and limited. You cannot send every small agent-generated change into an A/B test. Only tier-2 survivors should reach this stage.
The key engineering challenge is making tier 1 useful enough that the agent’s eight-hour run is not wasted. A practical way to test this is to look at your last 20 A/B tests. Plot the offline metric against the online business delta. If offline wins rarely translate into online wins, your metric is not ready for agentic optimization.
This is the part people often skip when they talk about agentic ML. They show the agent running experiments, but they do not always show whether the offline score actually predicts production value.
For new AI/ML engineers, this is the core takeaway:
Before you automate experimentation, make sure your evaluation actually points in the right direction.
What Stays Human
Once the substrate is in place, the agent can handle a surprising amount of day-to-day experimentation. It can try small architecture changes, tune hyperparameters, explore feature interactions, refactor training code, and compare incremental improvements.
But the most important decisions stay human.
Problem formulation stays human. Humans decide what the model is actually supposed to improve and what trade-offs are acceptable. For example, “increase revenue without hurting fairness” is not something you simply hand to an agent as a vague instruction. A human needs to translate that into metrics, constraints, and evaluation gates.
Composite metric design also stays human. This is one of the highest-leverage skills in production ML. A senior IC needs to understand how offline metrics behave, how business metrics move, where historical logs are biased, and why previous offline gains did or did not transfer to A/B tests.
Architecture decisions also stay human. Agents can implement DCNv2, a two-tower model, a new feature interaction block, or a different training recipe. But humans should decide whether that direction makes sense for the product, serving latency, maintainability, and long-term roadmap.
The same is true for decisions that may look worse in the short term but are better for the system. Removing a leaky feature may drop offline performance but improve generalization. Adding a fairness constraint may reduce AUC but make the system safer. Removing a legacy feature path may slow experimentation this week but reduce technical debt for the next year.
These are not simple metric-optimization decisions. They require judgment.
So the role of the ML engineer does not disappear. It shifts.
Instead of spending most of the time manually trying every small implementation idea, the ML engineer increasingly designs the contracts that agents operate inside. The work moves from “try this model change by hand” to “define the sandbox, metric, evaluation gates, and production constraints so an agent can safely explore.”
That is a different skill set from what many ML courses teach. It rewards engineers who understand not just models, but also systems, evaluation, product metrics, and failure modes.
Getting on the Next Evolution
Most teams do not need to jump directly into AutoMLOps. In fact, they probably should not.
If your training pipeline is not reproducible, fix that first. If your offline evaluation is unstable, fix that first. If your experiment tracking is messy, fix that first. AutoMLOps is not a replacement for MLOps. It sits on top of it.
The path from Stage 2 to Stage 3 is not a rewrite. It is a set of focused investments.
First, design a composite offline metric and measure how well it correlates with your business KPI. Pull your last 20 A/B tests and compare the offline metric against the online result. If your pure ML metric does not predict business movement, start adding a business proxy. This could be estimated revenue, estimated conversion, fraud loss prevented, retention proxy, or another signal that better reflects what the product actually cares about.
Second, tighten the immutable surface. Move your evaluation harness, leakage tests, fairness gates, and metric definitions into a protected area of the repo. Require senior review to modify them. Enforce that boundary in CI. This is useful even before agents enter the picture because it protects human-driven experimentation too.
Third, add compute guardrails. Set a wall-clock cap, per-experiment timeout, total budget, and kill switch. This matters because agents are very good at continuing to try things. That is useful only if the system has limits.
Fourth, make the training pipeline deterministic. Same code plus same data plus same seed should produce the same result, or at least close enough that small improvements are meaningful. If every run has too much noise, the agent will optimize noise as easily as signal.
These four investments make your MLOps stack better even if you never use an agent.
That is the practical way to think about AutoMLOps. It is not about chasing hype. It is about hardening your ML system so that automated experimentation becomes possible later.
The agent itself is cheap. Pointing Claude Code or Codex at a well-prepared repo is not the hard part. The hard part is preparing the repo, the metric, the evaluator, the sandbox, and the business-aligned scoring system.
That is where MLOps is heading.
The teams that invest in this substrate now will be in a much better position as coding agents improve. Not because they will blindly let agents ship models to production, but because they will have built the contracts that make agentic experimentation useful, safe, and measurable.
For new AI/ML engineers, this is the real lesson:
Do not only learn how to use agents.
Learn how to build the systems that make agents trustworthy.
And that’s ML Harness Engineering!
The framing around harness engineering as the missing layer in most MLOps setups is spot on. Most teams have the training and deployment pieces but no systematic way to evaluate and iterate in the feedback loop. AutoMLOps makes this loop a first-class concern, which is where the real productivity gain comes from.