

Building an End-to-End FAQ Chatbot with Continuous Training & Deployment: Pre RAG Era
My side project from 2019!

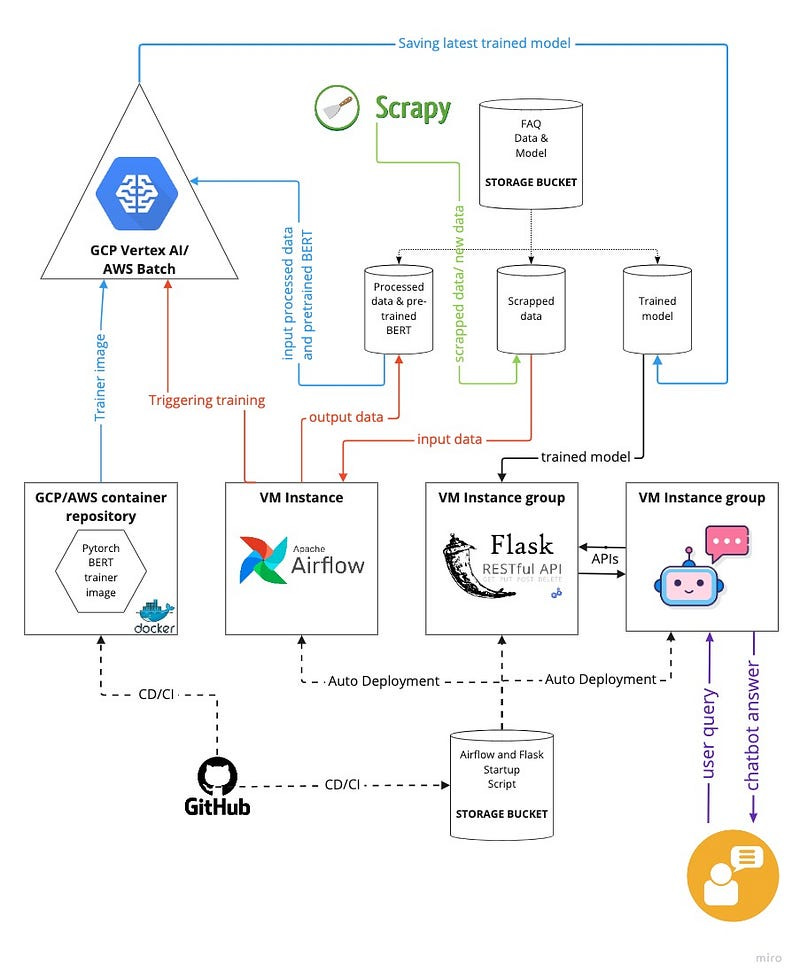
I created a FAQ Chatbot for my financial Robo-advisor website where users can type in general questions related to the finance world, and the Chatbot would present them with the closest answers from a pool of knowledge base. The Chatbot is constantly updated by adding new information to the knowledge base by manually forming new question-answer pair sets or by scrapping data from financial websites. Based on the newly added data, the FAQ Chatbot model is continuously fine-tuned and deployed and then served by an API to answer the users’ queries.
Given the difficulty of deploying and maintaining a ML model in production, the scope of the project was not limited to the development of the best model for the task, but to completely productionalize the task which includes continuous training, deployment, and integration using the best MLOps practices on a Cloud platform. The above architecture is the final outcome of this project.
Through this blog, I briefly touch upon each segment of the architecture and dive deeper wherever necessary. It goes without saying that there are multiple ways to achieve the same results and this blog presents one. This project was deployed on the Google Cloud Platform (GCP); however, the concept of the architecture can be easily transferred to other cloud providers such as AWS or Azure.

Objectives
The project can be divided into the following three stages:
Basic:
Train a S-O-T-A deep learning model for FAQ Chatbot based on financial domain data to retrieve the closest answer for a given query.
2. Intermediate:
Productionalize the FAQ Chatbot
Continuous training and monitoring using the MLOps best practices
Continuous deployment and integration of services with the Cloud Platform
3. Advance:
Make the architecture reproducible for other domain data eg. it can be easily adapted to the medical, education domain etc.
1. Basic — FAQ Chatbot BERT Model
As mentioned earlier, the purpose of the FAQ Chatbot is to retrieve the closest answer from the knowledge base for a given question. To serve this business case related to Finance, a training data FiQA-2018: Task 2 — Opinion-based QA was used initially. This data had thousands of finance-related question-answer pairs crawled from various financial websites.
In order to choose the best approach for developing FAQ Chatbot, the literature survey covered FAQ Chatbot architecture from using simple feature engineering/formula-based to Transformer-based. Given the performance, efficiency and superiority of the Transformer based architecture, different training/fine-tuning strategies w.r.t. BERT-based models for answer retrieval were experimented with using the FiQA-2018 data.

The FiQA dataset was transformed to fit the need for a pairwise fine-tuning approach using pre-trained BERT-based models. The model training setup was done in Pytorch and the whole setup was packaged into trainer and evaluator modules which allowed easy experimentation, hyperparameter tuning and evaluation with different pre-trained models. At the end of training and evaluation, the package outputs a fine-tuned model along with a metadata file and evaluation file in the respective folder which displays all the necessary information as shown in the below image. The same package is used in the further stage to create a container for continuous training.

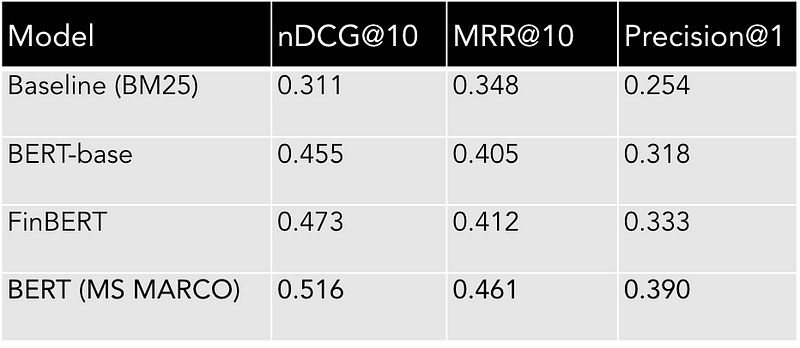
In one of the experiments, a BERT large model fine-tuned on the MS MARCO dataset (passage retrieval) was used to transfer and adapt to the FiQA-2018 dataset using a pairwise training approach. This model showed the most promising results compared to other models shown in the below table.
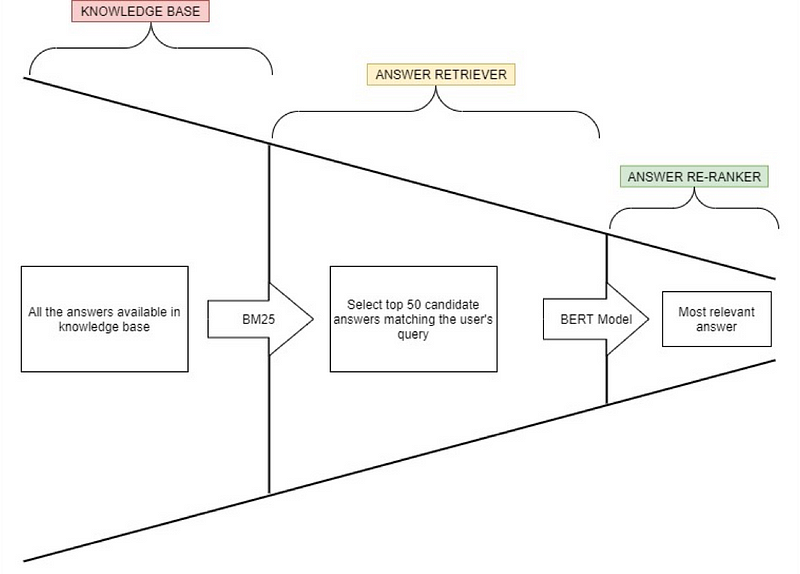
The answer retrieval process is divided into two stages as the transformer models would require very high resources and time to retrieve the closest answer for a given question from the huge knowledge base. The first retrieval stage i.e. answer retriever is done using BM25 based algorithm where the documents are indexed using Pyserini in Python and this stage fetches the top 50 candidate answers based on the user’s query. And later the fine-tuned BERT-based model is used for re-ranking the answers using the confidence score. The output of the model presents the top 1–3 ranked most relevant answers.
The same approach is used for the evaluation of the test dataset. The further sections dive deeper into Continuous training and serving and Continuous Integration, Delivery and Deployment.
2. Intermediate- Continuous training and serving
There are various MLOps frameworks and orchestrators such as TFX, MLFlow, KubeFlow, Airflow, etc. Few of these tools, such as TFX and KubeFLow, are complex and require very high computational resources. Instead, I built a custom setup to follow MLOps' best practices of continuously generating and processing new data, continuously training and deploying a new model, and continuously monitoring the results by making the results of the experiments trackable as displayed in the below image.

The whole setup was deployed on the Google Cloud Platform (GCP) using the free tier account.
2.1 Data Scrapping — Scrapy
The addition of new data was done by scrapping data from a financial website post acquiring the required permissions. Scrapy, a Python-based web crawler framework was set up and deployed on the GCP instance to scrap questions and answers from this website. Scrapy would daily or weekly scrap questions and answers and dump them in the structured date-based folder on the Storage bucket on GCP as shown in the below image.

Here, question.tsv and answer.tsv contains the question and answers scrapped, while ques_ans.tsv contain the mapping of questions and answers. The folder ‘2000–01–01’ holds the FiQA-2018 raw dataset in a tabular separated file. The metadata.json file stores the last training information of the FAQ Chatbot model. Human monitoring is required for the scrapped data before using it for retraining the FAQ chatbot model and adding the answers to the knowledge base.
Alike the raw data, the BERT — MS MARCO model, which showed the best results are used for the training of the FAQ Chatbot model using the Transfer and Adapt strategy. This model is saved in the same Cloud Storage bucket by the path: faqbot_bucket ->faq_model ->model ->pre_trained_model ->bert-msmarco.
2.2 Continuous training — Airflow
As new data gets added, the FAQ Chatbot’s performance to retrieve answers based on the newly added data gets poor. For example, if the FAQ Chatbot is mainly trained on banking-related question-answers, then the same model will not behave well on investment-related questions. Hence, with the addition of new data, re-training of the model is necessary to keep its performance high and generalise more. For continuous training, the Pytorch trainer-evaluator package was dockerized and pushed to the Google Cloud container registry using the CD/CI pipeline - GitHub Actions. This image is later used by Vertex AI for triggering the fine-tuning of the FAQ Chatbot.
For Airflow, a custom docker image is used to deploy Airflow with its dependencies on a Virtual Instance machine of Google Cloud for cost-effectiveness, instead of making use of ‘Cloud Composer’ — GCP-managed Airflow. The designed Airflow training pipeline looks as below.

The main responsibility of the Airflow pipeline is the collection, pre-processing, deduplication, and formatting of the newly scrapped data. In the next steps, the Lucene indexes for the answer-retriever stage, the processed data (pickled) — train, validation and test dataset for answer re-ranker model training and the updated knowledge base — answer collection are exported to the Cloud Storage bucket.
The Airflow pipeline is triggered daily or weekly and it checks if there is a substantial amount of new data added since the last training (metadata.json file is referred for the same), e.g. at least 200-500 new question-answer pairs have been added. Only if the condition is satisfied then all the further data preprocessing, generation and exportation steps are performed. In the final step of the Airflow pipeline, a training job to Vertex AI/AI Platform is submitted and is briefed in the further section.
2.3 Continuous training — Vertex AI/AWS Batch
In order to perform continuous training in Cloud, one can make use of VM instances for custom training. However, it becomes too expensive to maintain the running VM when the model is not training. Scripts can be written to turn on and terminate VM instances for training time, but it increases the complexity of the architecture. Vertex AI allows high flexibility and scalability with GPU and TPU support. It allows training models using custom images with hyperparameter optimization and makes it easier to integrate it with CI/CD environments and perform rollbacks.
As mentioned earlier, a custom container image of the FAQ Chatbot model trainer-evaluator module is created using Docker and pushed to Container Registry for the AI Platform/Vertex AI training service. With the image in the Cloud container repository, the below command in the last step of the Airflow triggers the model’s training i.e., initiating the AI Platform training job.

Here the hyperparameters set are obtained through experimentation and hyperparameter tuning. As part of the training, initially, all the required input files such as train, validation and test pickle files are downloaded in the container image from the Cloud Storage. Also, the BERT MS MARCO model is downloaded in the container as per the arguments passed. Post training and evaluation, the final fine-tuned model, the evaluation results, metadata, etc., are exported to the Cloud Storage bucket in a timestamp folder format, as shown in the figure below.
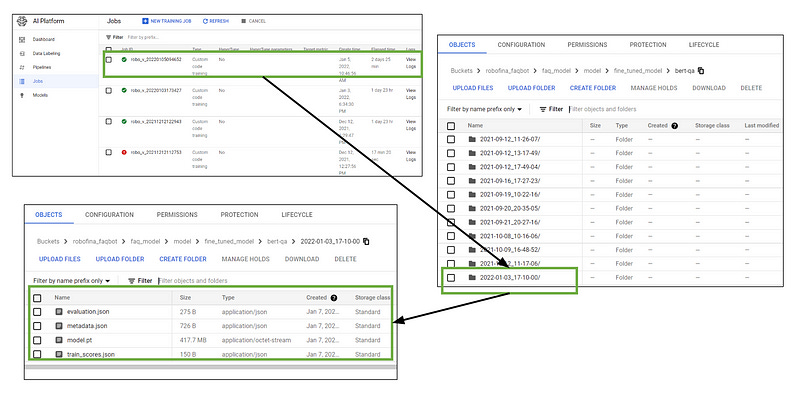
This setup also allows fine-tuning on other pre-trained models such as FinBERT by changing just one parameter i.e., bert_model_name. Then the final fine-tuned model is exported to the folder ‘finbert’ in the same folder structure as shown in the above image. Hence, making the setup very flexible in accepting new model training strategies and exporting the fine-tuned models and the evaluation scores to the Cloud Storage buckets. The same model is continuously deployed and used by the Flask API which serves the users’ requests.
2.4 Continuous model deployment and serving — Flask API
As the continuous training of the model is successfully set up, the FAQ Chatbot model can be communicated with an API where the input parameters are passed to the model and predicted processed results are passed back to the end user. The model serving is done by Flask API. An API endpoint with the GET request method accepts the user’s query as input and returns the top_n most relevant answers along with their probability scores using the funnel approach mentioned earlier. The default value of the top_n parameter is set in a config file as 3 and can be updated according to requirements.
This Flask API application is deployed on a Ubuntu-based VM instance with GPU support. As Flask is not a production-ready server, an Apache HTTP server is installed on top of the Flask service which passes the user request to the Flask API using the WSGI protocol. The VM instance of Flask API is deployed as part of an instances group on Google Cloud for easy scalability based on CPU utilisation and this instance group is further connected to the load balancer.
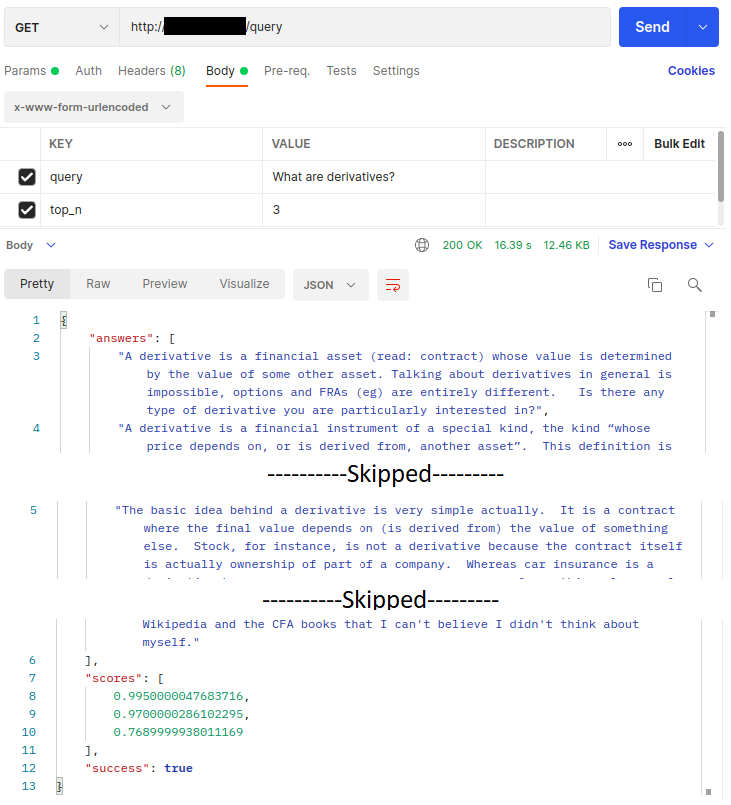
The setup and the model are also able to fetch the correct answers for which the question didn’t exist as part of the question-answer training data. For example, the training data didn’t have the question — ‘What are derivatives? ’, but the FAQ Chatbot model was able to get the correct answer from the knowledge base based on this question as seen in the below image. Hence, making the transformer-based language model super advantageous here.
With every successful Airflow pipeline run, the model and the dependent files should be updated in the Flask application. A simple cron job is set up as part of Flask application deployment for the continuous deployment of the latest FAQ Chatbot fine-tuned model, the latest knowledge base and the updated Lucene index from the previous stage. The cron job runs a Python script every n minutes, which checks and compares the latest model and related files on the Cloud Storage bucket with the ones used in Flask API.
Suppose a newly trained/fine-tuned FAQ Chatbot model is available along with an updated knowledge base and Lucene indexes. In that case, the Python script downloads and replaces the current model and the related files with the latest versions from the Cloud Storage bucket. Thus, the Flask API always uses the latest models and files which were generated after the successful run of the Airflow pipeline. This ensures that continuous training and deployment of the FAQ Chatbot BERT model following MLOps best practices are achieved; hence, accomplishing one of the primary intermediate objectives set at the beginning of the blog.
2.5 Continuous Integration, Delivery and Deployment
The previous section focused on deploying major services to implement end-to-end financial assistant FAQ Chatbot trained on the BERT-based model. It also discussed the continuous training and deployment of the BERT-based deep learning model. Besides the continuous training/ deployment of the deep learning model, the container image of the model trainer-evaluator module, the Flask API, the Scrapy service and Airflow DAGs are necessary to be automatically updated every time new changes and updates are done to their code.
As GitHub is used as the code repository for all the services, the CD/CI of these services is done using GitHub Actions. For example, after major changes in the trainer-evaluator FAQ Chatbot module, a new image is created and pushed to the Container Registry using GitHub Actions. This latest image is then used by the AI Platform/Vertex AI for the training and evaluation when triggered by the Airflow pipeline.

Along with the continuous deployment and integration of the services on the VM instances of Google Cloud, startup scripts were created to automatically create and set up an environment for the seamless initial deployment and start of these services on any VM instance of Google Cloud. This makes possible the scaling, replacement or recovery of the VM instances very easy. An example startup script for auto-deployment and initialization of Airflow is as below.

Setting up the Flask API and the Apache server is also done using the startup script. The Startup scripts and related dependencies are uploaded to the Google Storage bucket, and the location of the same is provided while creating the VM instance group template. When the VM instance is initialised, it downloads the script from the given location and executes it with Administrator privileges. GitHub Actions regularly pushes these Startup scripts and dependencies to the Google Cloud Storage bucket location whenever new changes are merged in the main branch of the Startup script repository.
3. Advance- Architecture reusability
The previous two sections covered the Basic and Intermediate objectives set at the beginning of the blog. According to the final objective, the architecture and setup created should be reusable for creating FAQ Chatbot specific to any domain, e.g. medical, education, sports etc. With the architectural setup explained in the previous sections, it is evident that the whole ecosystem can be used for different domain data.
With changes in the raw dataset, the fine-tuning of the model can be diverted to make the BERT-based model learn and fine-tune weights based on the new domain’s question-answer raw dataset, and everything else remains exactly the same. The continuous training pipeline will do pre-processing and all the steps mentioned in the pipeline and then use the new data for fine-tuning the BERT-based model using the Transfer and Adapt training strategy. After successful training, the new model, the knowledge base and the new Lucene indexes will be automatically deployed and used by the Flask API to serve the user query. The new model performance can be evaluated as the entire process remains the same.
Since the new data is adapted to a fine-tuned model based on the passage ranking task (MS MARCO), the trained model tends to perform well and does not require changes in the pre-trained BERT model. However, in the case of experiments, the setup can be easily used with other BERT or Transformer based pre-trained models. The model training and evaluation results are saved on the Cloud Storage bucket which can be used for performance evaluation and selection.
Hence, with just a change in the raw dataset, the entire implementation adapts and redirects itself to serve the user queries based on the new domain, making this scalable setup extremely easy to reuse on different domain datasets.
Conclusion
I hope I was able to conceptualize and develop a nice example and a cost-efficient end-to-end solution which can be applied to multiple ML use cases completely or partly. Also, due to the cloud’s free tier limitation, the services used were best fitted based on these limitations. I am sure the same results can be achieved by using different services or similar services on GCP or AWS or Azure.
No source code?
Does it feel good to label a glorified RAG system with all those terms?
I’ve never seen a more improper use of so many terms like e2e, training, etc..