



Solution to Sklearn Pipeline Custom Transformer Headache
Sharing templates to make your life easy!

Hey everyone 👋
Today, let's dive into one of the most powerful yet often tricky tools in machine learning: custom transformers in scikit-learn pipelines.
If you’ve ever scratched your head trying to pass two columns in and get one transformed column out, you’re not alone! 😅 Plus, there are times when you need to retain column names post-transformation for EDA, explainability (hello, SHAP values! 👀), or simply to keep track of your features. I’ve been there too, and today, I’m sharing my journey (with template code!) to make this process smoother.

This blog offers example templates of custom transformers with clear, hands-on examples to help you integrate them into your scikit-learn pipelines effortlessly. Let’s dive in! 🚀
🤔 Why Custom Transformers?
Scikit-learn offers many built-in transformers, such as StandardScaler for scaling, OneHotEncoder for categorical encoding, and SimpleImputer for handling missing values. But what if your data needs something unique?
Custom transformers let you create reusable code tailored to your dataset, ensuring every transformation is consistent and repeatable. Need to combine two columns into one? Or extract specific features from timestamps? Custom transformers have your back! 💪
🔄 Why Use Pipelines?
Before we dive into custom transformers, it's worth noting that tools like Airflow and Prefect handle large-scale workflows, but sometimes you need on-the-fly transformations during model training and inference.
Sklearn pipelines help maintain train-test split integrity (avoiding data leakage) and ensure each transformation is applied consistently. They automate processes (imputation, scaling, feature extraction) efficiently, integrate seamlessly with model training, cross-validation, and recent enhancements like caching steps, improved serialization, and better compatibility with pandas DataFrames make them even more relevant today. 🚀
🛠️ The Tools We’ll Use
We’ll use pandas for data handling, BaseEstimator and TransformerMixin from sklearn.base to build our transformers, and Pipeline and ColumnTransformer to bring everything together.
🧩 Templates for Different Transformers
Below are templates for various custom transformers in scikit-learn pipelines, each serving a unique purpose. These examples demonstrate how to handle different transformation needs in your machine learning workflows.
1. 🧱 One-to-One Column Transformer
This transformer takes a single column (like text data) and returns its length and also the column names. Handy, right?

Why This Matters: Extracting text lengths helps when analyzing text data, as length can be a valuable feature for classification or clustering. These are just examples, and you can modify them based on your needs when working with sklearn pipelines.
2. 🧪 One-to-More Column Transformer
Got timestamps? This transformer extracts both the month and time of day from them.
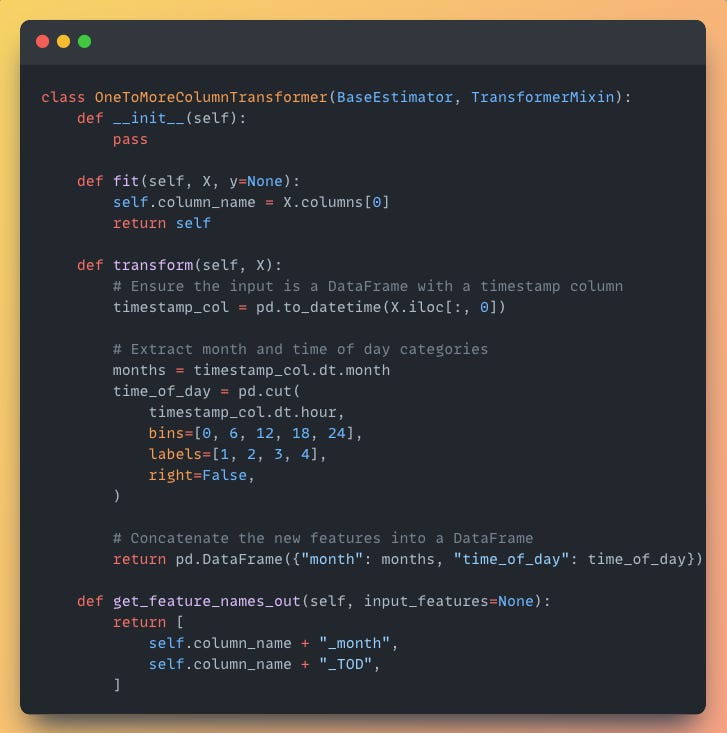
Why This Matters: Time-based features can improve models by capturing seasonality or time-of-day patterns. Another example could include extracting day of the week, week of the year, or even identifying holidays from timestamps, providing more granular insights for your models.
3. ✨ More-to-One Column Transformer
Normalize multiple columns and multiply them element-wise. Sounds fancy but super useful!

Why This Matters: Combining multiple features into one can simplify your data while retaining key relationships.
4. 📏 More-to-More Column Transformer
This one calculates the text lengths for multiple columns and outputs them.

Why This Matters: Generating new features from multiple columns enhances your dataset’s richness.
🏗️ Building Pipelines
We chain these transformers into pipelines for easy integration.
We use ColumnTransformer to apply these pipelines to specific columns in our dataset.

🚀 Final Thoughts
Building custom transformers can be unnecessarily daunting, but once you break it down, it's pretty straightforward (and kinda fun! 🤓).
Hopefully, this breakdown helps you avoid the headaches I faced. Keep experimenting, keep transforming, and stay tuned for more hands-on data science, MLOps, AI Agents, and LLM hands-on tips! ✨