



The Classical NLP Techniques That Still Matter Today
From BoW to Transformers: A dive into the techniques I’ve experimented with before the LLM revolution


Heylooo again! 👋
It’s 2025, and we’re deep into the LLM era where NLP isn’t just about rule-based techniques or even classical deep learning models. We’re working with LLMs, embeddings, retrieval-augmented generation (RAG), and AI agents that can reason, retrieve, and respond with great accuracy 🚀 (& some hallucinations)
Over the last 8 years of working in NLP, I’ve seen (and used!) everything from simple TF-IDF approaches to massive-scale language models. While LLMs have revolutionized the field, these foundational techniques are still incredibly valuable for understanding how modern NLP evolved and for efficiently solving smaller-scale problems.
This guide covers the most practical, effective, and cutting-edge NLP techniques I’ve worked with firsthand.
Let’s get into it! 🔥
1. NLP in 2025: What’s Changed?
Now we know that LLMs handle most of the heavy lifting effortlessly. But through experience, I’ve realized that understanding these foundational techniques still gives you an edge - whether it’s debugging a model, optimizing performance, or even improving modern NLP workflows or implementing pragmatism wherever possible.
Here’s a side-by-side of what I worked in the past vs. what many use now:

📌 2. Text Preprocessing: Still Essential!
Even in the LLM era, data quality matters. Garbage in, garbage out. Here’s a quick walkthrough of how text processing works:
Tokenization: Breaking text into words, phrases, or subwords. SentencePiece and FastTokenizers from HuggingFace are widely used.
Stopword Removal: Modern NLP models often handle this implicitly, but removing common words like “is” and “the” can still help in traditional models.
Normalization: Converting text to a standard format, such as lowercasing, stemming or handling special characters.
Text Cleaning: Removing unwanted symbols, HTML tags, and noise from text.
Handling Emojis & Special Characters: Some applications replace emojis with text descriptions to retain meaning.
🎯 3. Feature Extraction and Representation
Once we preprocess text, normally it needs to be converted in numerical format that a machine learning model can process. This step is crucial, as the choice of representation can heavily impact further model performance.
🔹 Bag of Words (BoW) and TF-IDF
Bag of Words (BoW) represents text by counting word occurrences, ignoring grammar and order. It’s simple but effective for traditional NLP tasks like text classification.
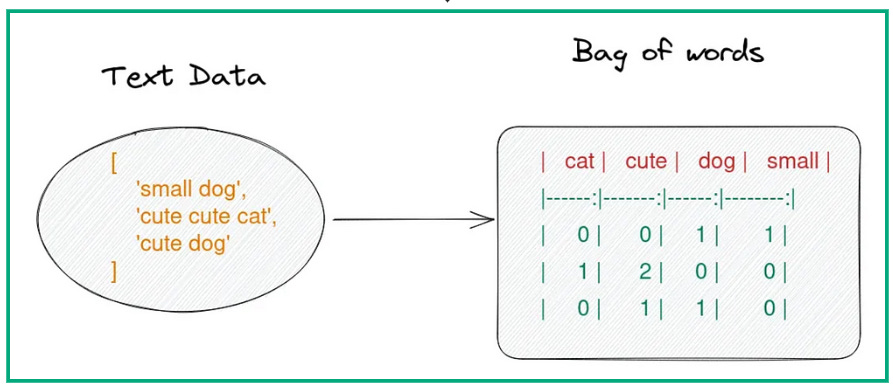
Term Frequency-Inverse Document Frequency (TF-IDF) improves upon BoW by assigning higher weights to rare but important words and lower weights to common words.
Key concepts:
N-grams & Skip-grams: Instead of single words, these capture short sequences of words to provide more context.
Sparse Matrices: Since most texts only contain a small subset of all possible words, we use sparse representations (like CSR format) to save memory.
Feature Hashing: Useful for large datasets, this technique converts words into fixed-length numerical features, reducing memory consumption.
When to use:
For document classification, sentiment analysis, and search applications where deep learning isn't feasible.
🔹 Word Embeddings
BoW and TF-IDF treat words as independent entities, ignoring relationships between them. Word embeddings, on the other hand, represent words in a continuous vector space, capturing their meanings and relationships.
Word2Vec
Word2Vec learns word meanings based on context. It has two primary methods:

Continuous Bag of Words (CBOW): Predicts a word from its surrounding context.
Skip-gram: Predicts the surrounding context given a word. Works better for infrequent words.
GloVe (Global Vectors)
Instead of predicting words, GloVe learns from word co-occurrence matrices. It captures global statistics of word relationships, making it more stable in some cases.
FastText
Developed by Facebook, FastText improves Word2Vec by using subword information, making it better at handling rare words or different word forms (e.g., “running” and “runner”).
When to use:
Word2Vec and GloVe are great for smaller tasks where deep models aren't needed.
FastText is useful for languages with rich morphology or rare words.
🔥 4. Deep Learning for NLP
Then came the era of neural networks - a time when traditional machine learning methods hit their limits, and we needed more powerful models to capture the complexity of language.
This was pre-transformer NLP, where we relied heavily on Recurrent Neural Networks (RNNs), Convolutional Neural Networks (CNNs), and later, Sequence-to-Sequence (Seq2Seq) models before transformers changed the game.
🔹 Recurrent Neural Networks (RNNs)
RNNs process text sequentially, maintaining memory of previous words. However, they suffer from vanishing gradients, where important information from earlier parts of a sequence gets lost as it travels through long chains of computations. This was incredibly frustrating—I remember training RNNs and watching them struggle to learn anything meaningful from longer texts, no matter how much I tuned hyperparameters. The deeper the network, the worse the problem became, making it nearly impossible to model long-range dependencies effectively.

Long Short-Term Memory (LSTM)
LSTMs solve the vanishing gradient problem using gates:
Input gate: Decides what information to add.
Forget gate: Removes irrelevant information.
Output gate: Outputs the relevant information.
Gated Recurrent Unit (GRU)
GRUs are a simplified version of LSTMs, using fewer parameters while maintaining similar performance.
When to use:
LSTMs/GRUs are useful for text generation, speech recognition, and sequence modeling.
🔹 Convolutional Neural Networks (CNNs) for NLP
While CNNs were originally designed for image processing, they turned out to be surprisingly effective for NLP tasks like text classification, sentiment analysis, and named entity recognition. Instead of processing sequences word by word like RNNs, CNNs detect patterns in text using filters, similar to how they identify features in images.
1D Convolutions: Capture relationships between nearby words.
Character-level CNNs: Work directly on characters, useful for noisy data (e.g., tweets, misspellings).
CNN-RNN Hybrid Models: Combined CNNs for feature extraction with RNNs for sequential dependencies.
CNNs were fast and efficient, making them a popular choice for NLP applications before transformers took over.
🔹 Sequence-to-Sequence (Seq2Seq) Models
The Seq2Seq architecture was a game-changer for translation, text summarization, and chatbots. It introduced an encoder-decoder structure, where the encoder processed input text into a hidden representation, and the decoder generated output text step by step.

Attention Mechanisms: Helped models focus on relevant words in longer sequences.
Beam Search: Allowed models to generate more fluent, natural-sounding text.
Seq2Seq models improved text generation significantly, but they still suffered from long-term dependency issues and were difficult to parallelize - making them slow to train.
And then, something revolutionary happened. 🎇
🔹 The Transformer Model: A New Era Begins
In 2017, transformers changed NLP forever. Introduced in the paper Attention Is All You Need, transformers solved everything Seq2Seq struggled with:
Self-Attention Mechanism: Let models look at all words in a sentence simultaneously, rather than step by step.
Positional Encoding: Helped preserve word order, something CNNs lacked.
Massive Parallelization: Made training incredibly fast and efficient.
This led to models like BERT, GPT, and T5, which now power almost every modern NLP system.
And that’s how the next era of NLP began. 🚀
I’ve experimented with all these techniques, and even in the age of LLMs, many core concepts still hold value. Understanding them helps in working with modern AI and appreciating how we got here.
But do I miss those classical NLP days? Actually not 😆
I hope this article was helpful! Did any of these techniques bring back memories (or nightmares 😅)? What are YOU working on? Drop a comment—let’s chat! 😊