

The Infrastructure That Powers RAG Systems
Mother of AI Project, Phase 1: Week 1


Infrastructure First, AI Second
⚠️ 85% of AI projects fail before they ever reach users.
Not because of bad models because of bad infrastructure.
Hey there 👋,
Welcome to the lesson one of “The Mother of AI” - Zero to RAG series!
What is The Mother of AI Project?
A hands-on, no-fluff AI course series built by engineers who’ve shipped GenAI systems in production.
Each phase focuses on real-world systems, not toy demos. And each teaches engineering practices that scale, using tools like Docker, FastAPI, Airflow, Ollama, LangGraph, OpenSearch, Langfuse, and more.
You’ll learn how to think and build like a true AI/ML engineer through systems that matter, with patterns you can reuse in your career.
The Project Roadmap
1️⃣ Phase 1: RAG Systems
Build a personalized AI research assistant for papers (this phase!)
2️⃣ Phase 2: AI Agents
Decision-making agents using LangGraph, tools, memory
3️⃣ Phase 3: Recommendation Systems
Real-time user/item ranking, hybrid models, feedback loops
4️⃣ Phase 4: MLOps & LLMOps
Deploy, observe, evaluate, and scale ML/LLM workflows
5️⃣ Phase 5: Full App Integration + Cloud Deployment
CI/CD pipelines, infra-as-code, cost monitoring
6️⃣ Phase 6: Monitoring & Alerting Mastery
Drift detection, error logging, alert pipelines
Who Is This For?
Whether you’re:
A student working on your first real AI project
A Data Scientist levelling up on software + infra
A Backend Engineer curious about RAGs or LLMs
An ML Engineer ready to move into GenAI
This is for you.
You’ll go from scratch to a scalable production RAG system, one week at a time. For phase 1 we keep it free (blog + code are FREE), with optional paid Office Hours for live support and deep dives.
Important: If interested in Code walkthrough and explanation videos (PAID)
Check below:
✅ Live walkthrough of that week’s code
✅ Deeper insights into design tradeoffs, infra, and architecture
✅ Debugging support on your implementation
✅ How to go beyond and deploy these solutions in production
Course → https://jamwithai.dev/
Use Coupon code - JMJCAWJ64E to get 30% discount.
The Problem We're Solving
"I'm drowning in research papers, and Google search isn't cutting it anymore."
You wake up, check Twitter, and see 47 new AI papers dropped overnight. arXiv shows 200+ new submissions in Computer Science. Your reading list grows from 15 to 847 papers you "should definitely read."
You want papers on "attention mechanisms in multimodal transformers" but:
Google Scholar gives 50,000 generic results
arXiv search misses semantic relationships
ChatGPT gives outdated answers from 2021 training data
Manual browsing takes hours and you still miss relevant work


We built RAG systems in production that serve millions of queries. This exact frustration led us to create what you're about to build: an arXiv Paper Curator that actually solves the research discovery problem.
By now, everyone knows what RAG (Retrieval-Augmented Generation) is. If not, here's the elevator pitch:
RAG combines search with language generation to give you contextual, accurate answers from your own knowledge base instead of generic responses.
arXiv Paper Curator
Here's what we're building together over the next 6 weeks - a production-grade RAG system that solves the research discovery problem.
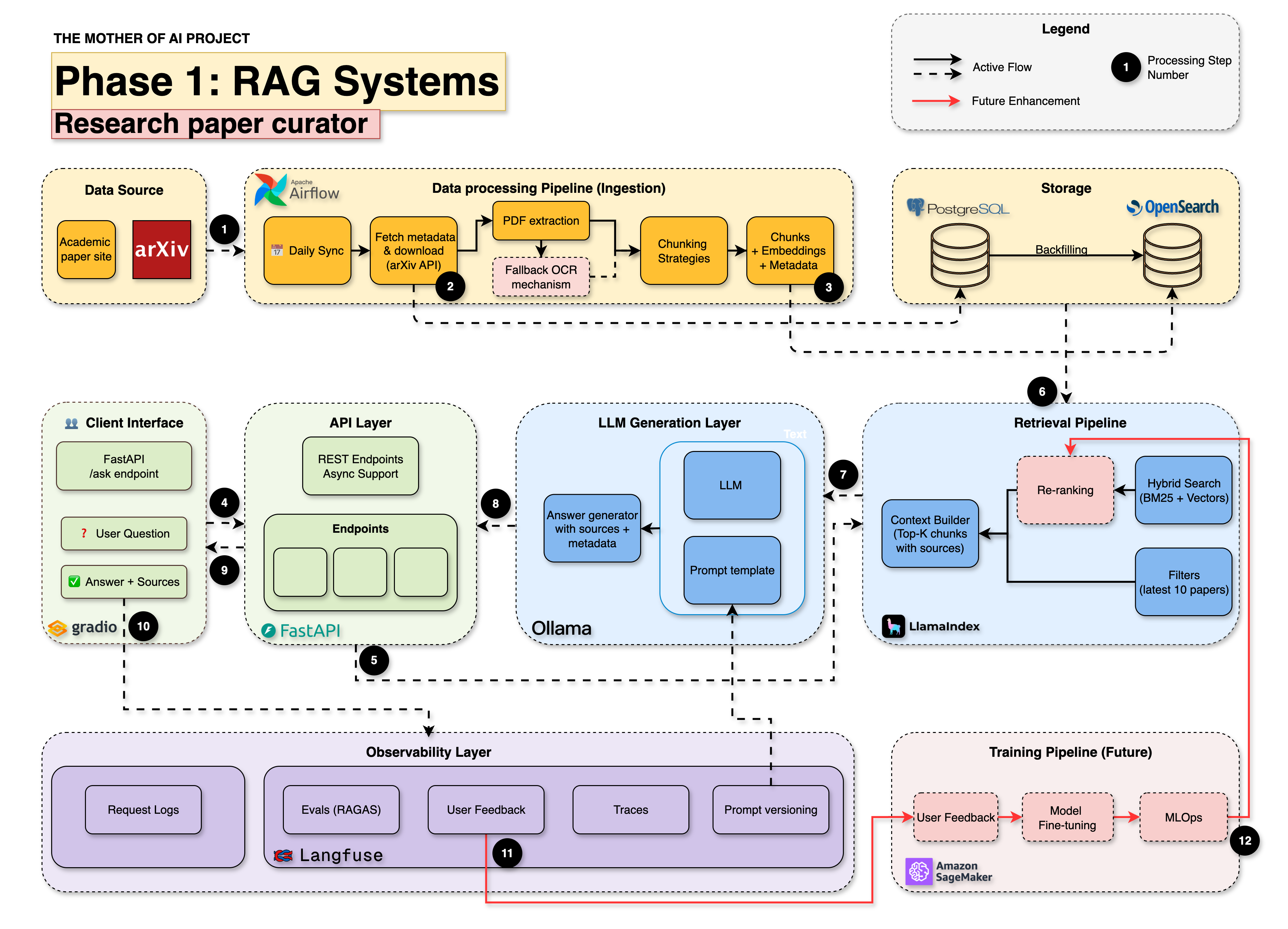
You’ll build a complete research assistant that:
Runs automated data ingestion pipelines
Downloads and Parse 100+ academic PDFs (e.g. arXiv papers) through APIs
Search across papers with keywords and embeddings
Answer questions using local or foundational LLMs (Ollama, OpenAI, etc.)
Show sources, give feedback, and maintain privacy
A complete real production grade system!
This is what we call the ArXiv Paper Curator - an AI system that turns the flood of new AI research into structured, searchable knowledge.
What you’ll build (Technical Breakdown)
You will build from scratch - a fully local with API integration, production-grade RAG system with:
Data Ingestion: Auto-download PDFs daily from arXiv using Airflow
PDF Parsing: Extract structured content via Docling
Metadata Storage: Store authors, titles, abstracts, etc. metadata in PostgreSQL
Search Engine: Use OpenSearch with BM25 + semantic vectors (hybrid)
Chunking Engine: Evaluate different chunking
RAG Pipeline: Query expansion + retrieval + prompt templating
Local LLM: Answer questions using Ollama or API (LLaMA3, OpenAI, etc.)
Observability: Use Langfuse for prompt versioning, tracing, quality
Frontend: Ask questions and explore results via Streamlit or Gradio
FastAPI Backend: Async API server for integration and extensions
Dev Best Practices: uv, ruff, pre-commit, pydantic, pytest, logging, etc.
This isn't just another tutorial project - it's a complete production system that handles real-world complexity.
But here's the catch:
Building a RAG system that actually works at scale one that can handle thousands of papers, provide sub-second responses, and give accurate answers requires production-grade infrastructure from day one.
This is why we're starting with infrastructure, not the "fun" AI parts.
What Makes This Different
Traditional RAG Tutorials:
Skip infrastructure entirely
Use toy datasets and simple examples
Deploy to Streamlit and call it "production"
Focus on accuracy metrics only
Our Production Approach:
Infrastructure as a first-class citizen
You learn by learning the tools and components used in real world infrastructure
A clear roadmap with learning materials
Real-world data pipelines and error handling
Modular architecture that scales
Performance, reliability, and cost considerations
This is how you build RAG systems that actually work at companies, not just in demos.
Why Infrastructure First?
We recently ran a RAG systems workshop at a university. Students were excited to learn about embeddings and vector search.
Three hours later, half the class was still wrestling with Docker containers and database connections. The other half had given up.
The Common Pattern We See:
"My container keeps crashing"
"OpenSearch won't accept connections"
"FastAPI gives me import errors"
"Docker says 'port already in use'"

That's when it hit us:
The gap between AI tutorials and production reality isn't the algorithms - it's the infrastructure.
For production use case, we need to make sure our systems have:
Robust Infrastructure - Services that don't crash under load
Clean Architecture - Code that teams can maintain and extend
Observability - Monitoring that tells you what's actually happening
Automation - Pipelines that run without human intervention
In real production companies, we build modular systems. You start with solid infrastructure, then add specialized components on top. That's exactly what we're doing here.
The Production Mindset:
Infrastructure failures kill more AI projects than bad algorithms
Modular architecture enables team collaboration and system evolution
Automation prevents the "works on my machine" problem
Monitoring helps you understand system behavior before things break
The Production Pattern:
Week 1: Infrastructure foundation (APIs, databases, orchestration)
Week 2: Data ingestion pipelines
Week 3: Search and retrieval
Week 4: Chunking and evaluation
Week 5: Full RAG system
Week 6: Production optimization
Lesson 1: Building Your Production Foundation
This week, you're not just "setting up Docker." You're building the infrastructure backbone that every production RAG system needs.
What You'll Build
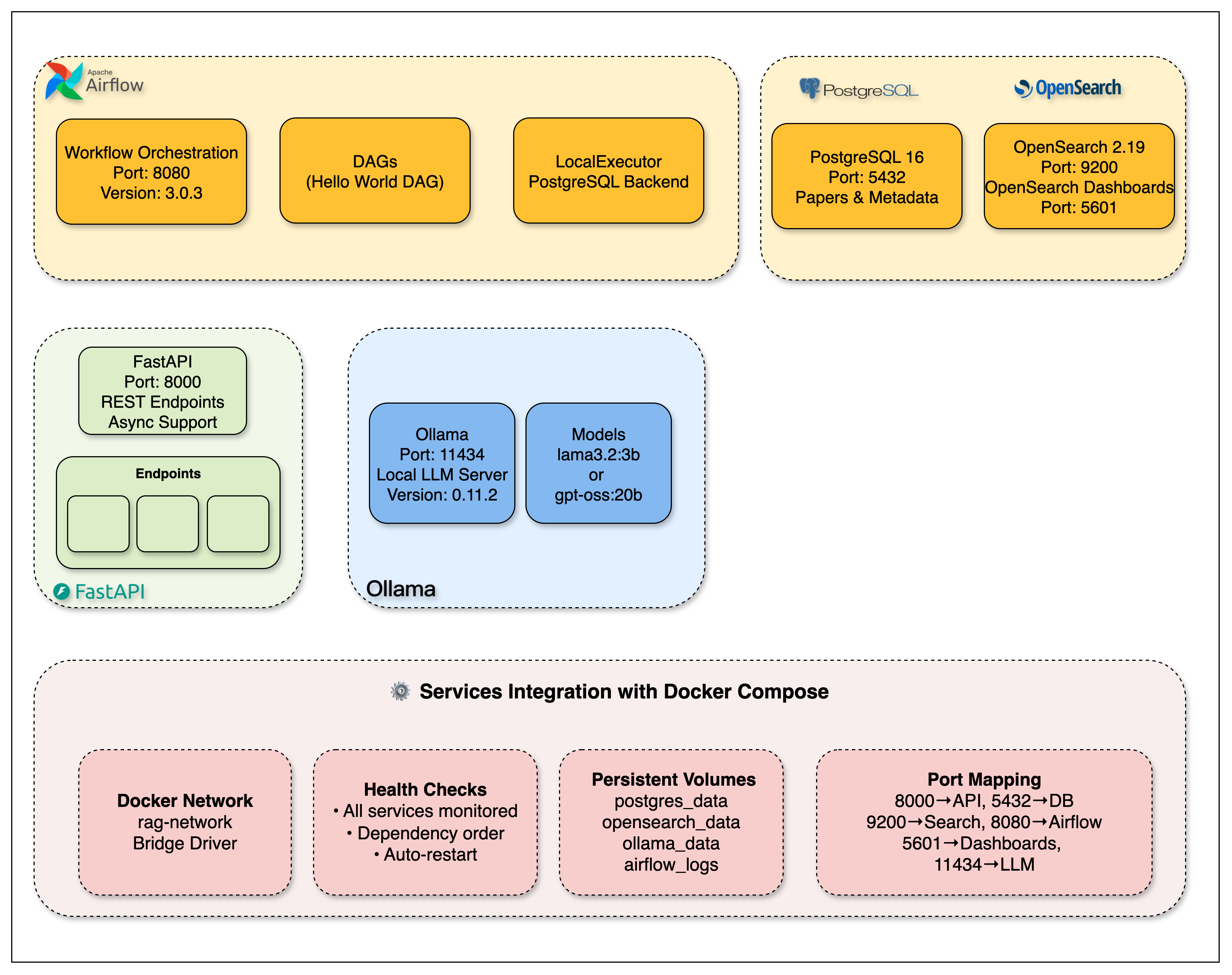
Complete Production Stack:
FastAPI Backend
Async endpoints with comprehensive swagger documentation
Pydantic models for request/response validation
Dependency injection for database sessions
Error handling middleware for production reliability
Health check endpoints for monitoring
PostgreSQL Database
Optimized schema for academic paper metadata
JSONB columns for flexible document storage
Proper indexing for fast queries
Connection pooling for concurrent users
Database migrations for schema evolution
OpenSearch Cluster
Custom analyzers for scientific terminology
Hybrid search combining BM25 + vector similarity
Index templates optimized for document retrieval
Cluster health monitoring and alerting
Query performance optimization
Apache Airflow
DAG orchestration for automated paper ingestion
Retry logic and failure handling
Task dependency management
Monitoring dashboard for pipeline health
Scalable task execution
Ollama Container
Local LLM inference with no external dependencies
Resource allocation and performance tuning
API endpoints for question answering
Privacy-first AI processing
Docker Compose Orchestration
Service dependency management
Health check configuration
Network isolation and security
Volume mounting for data persistence
Environment variable management
Getting Started
Ready to build production RAG infrastructure?
Here is the code for the first week:
Week1 github link - https://github.com/jamwithai/arxiv-paper-curator
Along with the code, we've created a comprehensive Jupyter notebook that guides you through every step:
Week1 notebook - https://github.com/jamwithai/arxiv-paper-curator/tree/main/notebooks/week1
Clone the Repository: Get the complete codebase and Week 1 materials
Install Prerequisites: Python 3.12, UV package manager, Docker Desktop
Run the Setup:
docker compose up -dto start all servicesOpen the Notebook: Launch
notebooks/week1/week1_setup.ipynbExplore Interactively: Test each service and follow the guided exploration
This isn't just documentation, it's your interactive guide that:
✅ Environment Verification: Checks Python version, Docker status, and prerequisites
✅ Service Health Monitoring: Real-time status of all 6 infrastructure components
✅ Connection Testing: Validates database connections, API endpoints, and service communication
✅ Interactive Exploration: Click links to explore FastAPI docs, Airflow dashboard, OpenSearch interface
✅ AI Model Setup: Downloads and tests Llama 3.2 (1.2GB) for local inference
✅ Troubleshooting Guide: Built-in diagnostics for common setup issues
✅ Production Insights: Tips and patterns used in real production systems
The notebook also gives you learning materials to learn the components.
Success Metrics for Week 1:
All 6 services running and healthy
FastAPI documentation accessible at localhost:8000/docs
Ollama model downloaded and generating responses
OpenSearch and PostgreSQL accepting connections
Airflow dashboard accessible with workflows visible
NOTE: We are also hosting weekly PAID Live Code Walkthrough and Q&A session
Register here -
https://topmate.io/shantanuladhwe/1657955(expired as the sessions started on 10th August, we will have another cohort for phase 1 soon)
Production Code Structure

Why This Structure? This is the modular architecture pattern used in production systems. Each layer has clear responsibilities, making the system maintainable and scalable.
Layer-by-Layer Breakdown:
Routers Layer (src/routers/)
FastAPI endpoint definitions
Request validation with Pydantic models
Response serialization and error handling
API documentation and examples
Authentication and authorization (coming in later weeks)
Services Layer (src/services/)
Business logic implementation
External API integrations (arXiv, OpenAI)
Complex data processing workflows
Caching and performance optimization
Error handling and retry mechanisms
Repositories Layer (src/repositories/)
Database abstraction and operations
Query optimization and indexing
Transaction management
Data consistency and integrity
Migration and schema management
Models & Schemas (src/models/, src/schemas/)
Database models with SQLAlchemy
API request/response models with Pydantic
Validation rules and data transformation
Type hints for better code maintainability
Why This Matters for Production:
Team Collaboration: Multiple developers can work on different layers simultaneously
Testing: Each layer can be unit tested independently
Scalability: Swap implementations (e.g., different databases) without changing other layers
Maintenance: Bug fixes and feature additions are contained within specific layers
Next Week: We build automated data ingestion pipelines that fetch and process hundreds of arXiv papers daily. The real fun begins! 🚀
Follow Along: This is Week 1 of 6 in our Zero to RAG series.
Every Thursday, we release new content, code, and notebooks.
Let’s go 💪
Subscribe to not miss the journey from infrastructure to production RAG system.
Thank you. This seems like a great project to learn from. Unfortunately, I don't feel that I have the necessary skills to start with this project or join the paid webinars yet. I only know Python out of all the tools you mentioned, and familiar with Docker, but have no production experience.
1. Do you have any plans to make a video course for these projects? I'm willing to pay for it and learn.
2. Or, do you think that joining your weekend webinars would be sufficient to learn the necessary skills on the go?
3. If not, do you recommend any structured courses to learn these tools and make myself ready to get started with this project?
I'm curious to hear your thoughts.
Thank you both for sharing your work and progress :)
I'm facing an issue when running docker compose up -d. While building the Airflow container, I get the following error. I have tried different ways to solve it but haven’t succeeded. If anyone has faced the same issue and knows the solution, please reply. Dockerfile:10
--------------------
9 | # Install system dependencies
10 | >>> RUN apt-get update && \
11 | >>> apt-get install -y --no-install-recommends \
12 | >>> build-essential \
13 | >>> curl \
14 | >>> git \
15 | >>> libpq-dev \
16 | >>> poppler-utils \
17 | >>> tesseract-ocr \
18 | >>> && rm -rf /var/lib/apt/lists/*
19 |
--------------------
failed to solve: process "/bin/sh -c apt-get update && apt-get install -y --no-install-recommends build-essential curl git libpq-dev poppler-utils tesseract-ocr && rm -rf /var/lib/apt/lists/*" did not complete successfully: exit code: 100