

The Production AI/ML Engineer's Guide to A/B Testing
Beyond split traffic and a t-test. Five strategies, when to use each, what they cost.


Hi there 👋,
If you build or ship AI systems for a living, you've probably felt this in the last year or so. The slow part of the job used to be getting something into production. It isn't anymore, and that quietly changes what the rest of the work looks like.
AI has collapsed the time it takes to build a model. Generating ten prompt variants, swapping a base LLM, retraining a reranker, fine-tuning a candidate generator, or spinning up an entirely new RAG pipeline now takes a few days, not a sprint.
The bottleneck on shipping has moved accordingly. The hard question is no longer “how fast can we build the variant?”. It is “how fast can we measure whether the variant actually worked?”.
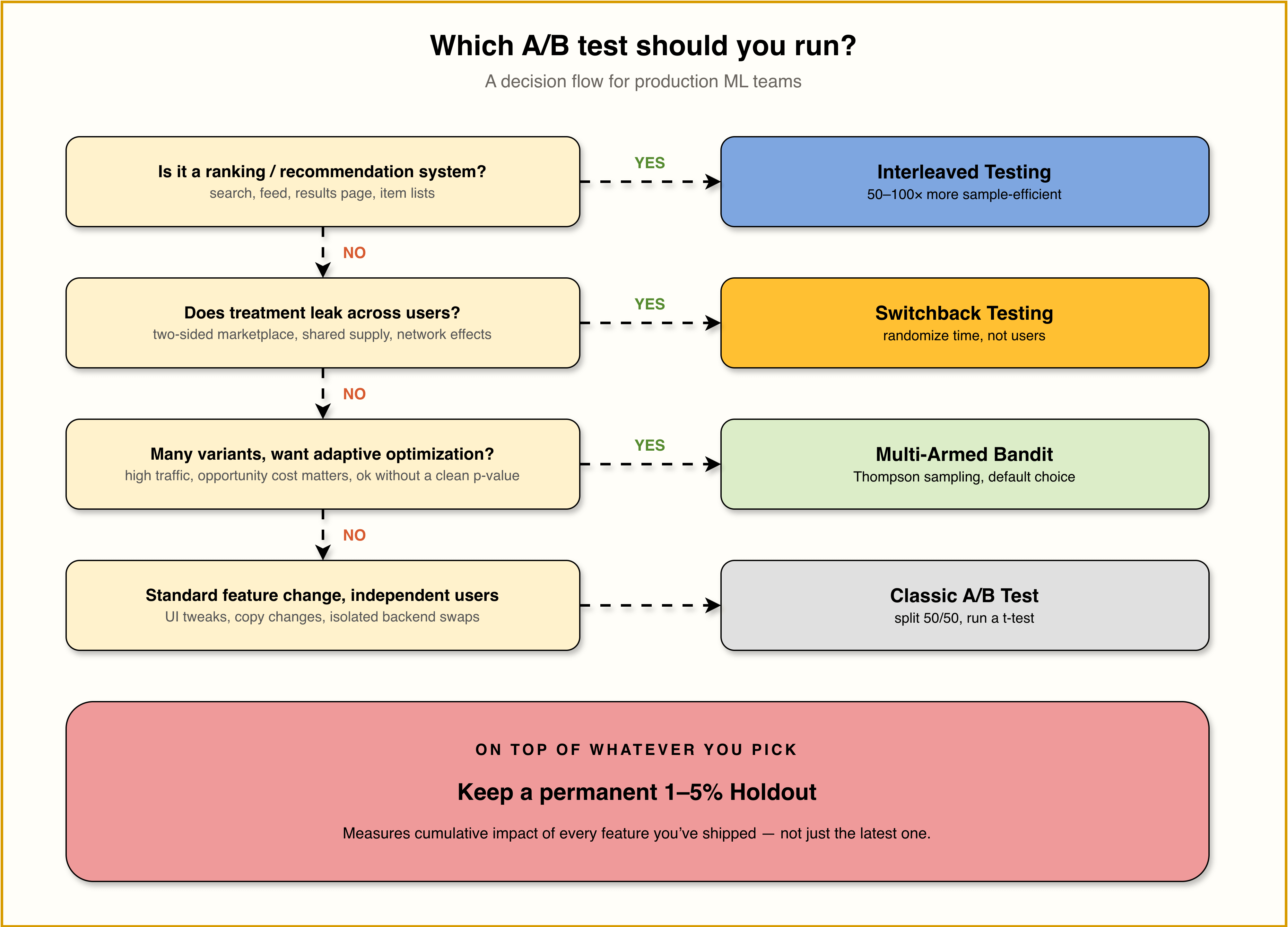
You can have ten experiments queued for next quarter, but only two of them can run live on the same surface at the same time without contaminating each other, and every test that takes a month to reach significance is a month the rest of your roadmap waits behind it. Knowing the full scope of A/B testing frameworks, and which one fits the problem in front of you, is what separates a team that ships from a team that watches a backlog grow.
The default A/B test (split traffic 50/50, run for two weeks, t-test the result) is what we all learn in our first stats course. It works. It is also the slowest, most insensitive, most opportunity-cost-heavy way to make a decision in production.
For most ML systems, classic A/B is the wrong tool. The technique you reach for should depend on the shape of the problem: interleaved tests for ranking systems and RAG retrievers, switchback for two-sided marketplaces and shared-supply systems, bandits for high-traffic decisions with many model or prompt variants, and a permanent holdout for measuring the cumulative impact of every model change you have shipped.
This post walks through all five. What each one does, when to reach for it, and the trade-off you are signing up for.
Applied AI Conference in Berlin - Sponsored

If you're building or running AI systems in production and you're anywhere near Europe, the Applied AI Conference in Berlin on May 28 is worth the trip. The line-up is amazing!
Free tickets for the Jam with AI community: We have a small number of free tickets to give to readers of this newsletter. If you want one, fill out this short form and we will send the details. First come, first served.
We will be there. And looking forward to catchup with you in the conference.
1. Classic A/B Test
The baseline everyone learns. Split traffic 50/50, run for two weeks, t-test the result.
It works for the right kind of problem, but the math is unforgiving ;) Detecting a 1% lift on a metric with realistic variance can require months of traffic, and for the kinds of changes AI/ML teams ship most often (embedding swaps, prompt tweaks, ranker re-weights, anything subtle), you will burn quarter after quarter and never reach significance. (must also check A/B test based on Bayesian theorem)
Use it when users are independent of each other, the change is isolated to a single surface, and the effect size is large enough that you actually expect to see it in a reasonable test window. In an ML setting, this usually means changes around the model rather than changes to the model: a redesigned recommendation widget on the homepage, a new onboarding flow for an AI feature, a UI change in how an LLM’s output is presented, or an infrastructure swap that is supposed to be quality-neutral and you just want to confirm it is. Anything where one user’s experience does not affect another’s, and the change is big enough that two weeks of traffic can detect it.
The trade-off is opportunity cost. Half of your users are stuck on the losing variant for the entire test window, and on low-traffic surfaces you may never accumulate enough samples to declare a winner at all. For most actual model changes, you should be reaching for one of the techniques below before reaching for this one.
2. Interleaved Testing
This is the one most AI/ML teams under-use, and the cheapest power-up you can give a ranking or retrieval team.
The mechanic is simple. Instead of splitting users between ranker A and ranker B, you blend their outputs into a single result list shown to the same user, then observe which side’s items get the engagement signal. In a search or feed system, that signal is clicks. In a RAG pipeline, it is which chunks the LLM actually grounds its answer on, or which ones the user expands or upvotes. The same user, in the same session, evaluates both rankers simultaneously.
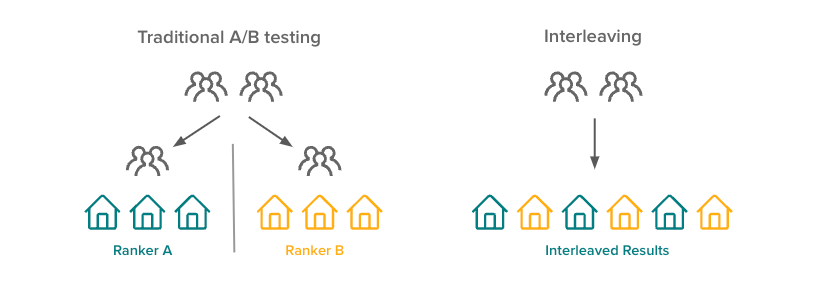
The sample efficiency is dramatic. Airbnb measured a 50× reduction in samples needed to reach the same statistical power as a classic A/B test on the same ranking problem, and Netflix, DoorDash, Bing, and Yandex all use interleaving in production for search and recommendations.
Why it works: interleaving removes between-user variance from the experiment. The noisy question a classic A/B asks is “do users in cohort A click more than users in cohort B?”, and the answer is dominated by who happened to get bucketed where. Interleaving replaces that with a much sharper question: given two items shown to the same user at the same moment, which one did they engage with? Same user, same context, same intent. You are measuring the ranker, not the cohort.
Use it when the system under test produces a ranked output that gets compared against alternatives. A search ranker, a feed ranker, a recommendation candidate generator, or the retriever in a RAG pipeline are all canonical fits. It is especially valuable when you cannot afford the months a classic A/B would need to converge, which is most of the time for retrieval and ranking work.
The trade-off is two-fold. Interleaving is purpose-built for ranked lists and does not translate cleanly to non-ranking decisions like prompt selection or classifier thresholds. And the analysis is a step trickier than a t-test. Team-draft interleave (TDI), probabilistic interleave, and balanced interleave each have different bias and variance properties, and picking the right variant for your traffic pattern matters more than it does for a standard A/B.
3. Multi-Armed Bandit
Bandits flip the script on traffic allocation. Instead of locking the split at 50/50 and waiting for the test to complete, they shift traffic toward the winning variant continuously, in real time, based on what the data is showing so far.
Thompson sampling is the default choice in 2026. It outperforms epsilon-greedy in nearly every production setup I have seen and degrades gracefully when traffic is sparse. UCB is fine but less popular outside academic settings.
The right time to reach for a bandit is when opportunity cost dominates the decision and you have several variants to compare at once. Modern AI products have a lot of these. Choosing between multiple LLM prompt variants for an in-product feature is the classic case: an LLM can generate dozens of prompt candidates in an hour, but you can only afford to let one of them serve production traffic. Same story for AI-generated headlines, push notification copy, email subjects, or product descriptions where the model produces a long candidate list and the bandit converges on the best one per user segment. The pattern also works for comparing several fine-tuned model versions of the same recommender at once, or for choosing between agent strategies (which planner to use, which tool to call first) when you have a few reasonable options and want the system to learn which works best in the wild.
Use it when traffic is high, you have several variants to evaluate at once, and the question you actually care about is “which variant wins?” rather than “by exactly how much?”.
The trade-off is reporting. Bandits are excellent at picking a winner but poor at producing a clean lift number for the slide deck. If your VP wants a 95% confidence interval and a p-value attached to the launch, you will have a conversation. Bandits cleanly answer “which variant is best?”. They do not cleanly answer “by how much, with what certainty?” in the way a frequentist A/B test does.
4. Switchback Testing
The only honest way to test in a two-sided marketplace, or any system where treatment leaks across users through shared resources.
The failure mode of classic A/B testing in this setting is brutal. If you randomize users between treatment and control on Uber’s pricing algorithm, both groups still compete for the same pool of drivers. Treatment users pay surge prices, supply shifts toward them, and control users see worse availability than they would in a world where the treatment did not exist at all. The treatment effect leaks through shared supply, your readout is contaminated, and you have measured nothing useful.
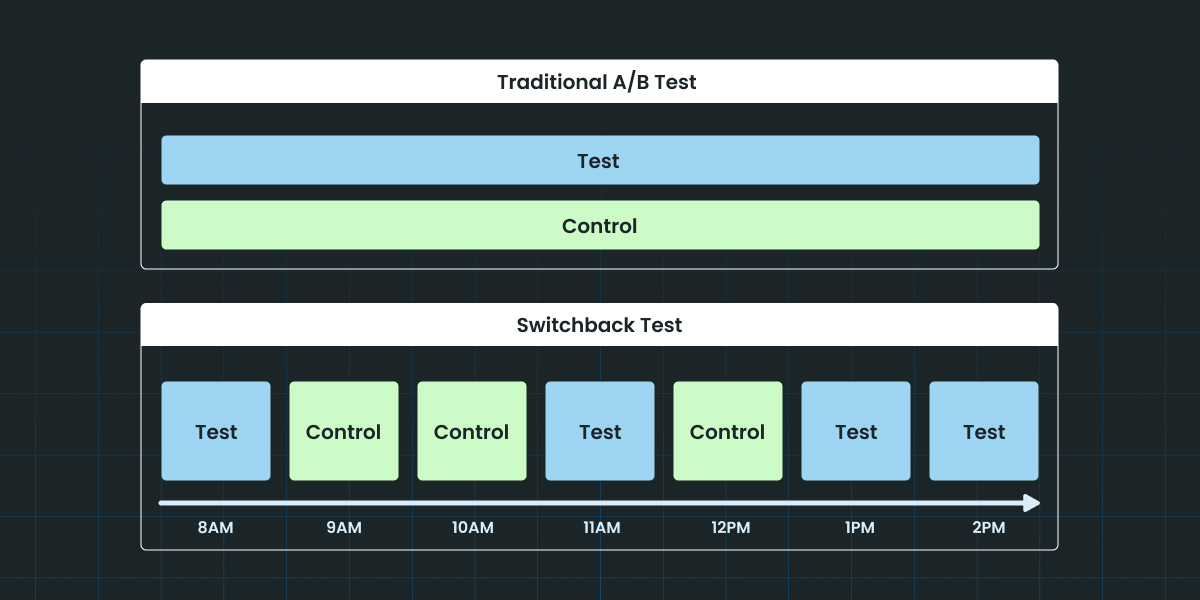
Switchback fixes this by randomizing time instead of users. The entire market runs variant A for one window (say, an hour), then variant B for the next window, then back to A, and so on. Each window becomes its own A or B observation, and because everyone in the market is on the same variant at the same time, there is no leakage of the treatment effect through shared supply.
Uber, DoorDash, and Airbnb all use this approach in production for their core matching and pricing ML systems, and their engineering blogs on the topic are required reading. The math is non-trivial. Consecutive windows are correlated, so you need cluster-robust standard errors at minimum, and you have to think carefully about how long each window should be relative to the carryover effects of your treatment. But for two-sided platforms, switchback remains the only honest method.
Use it when the system you are testing has users or agents competing for finite resources, or anywhere your treatment changes the equilibrium in ways that bleed into the control group. The canonical cases are marketplace pricing, ride or order matching, supply allocation, and ad auction logic. The same logic increasingly applies to AI systems with shared external constraints: a recommendation system surfacing limited-stock inventory where the treatment ranker steers users toward items the control would have shown, or an agent system whose actions consume a shared external resource (API quota, GPU pool, a queue) so that a more aggressive treatment policy actively degrades the control group’s performance.
The trade-off is that switchback gives you lower statistical power per unit of calendar time than a classic A/B would, it is more sensitive to time-of-day and day-of-week confounders, and the analysis is harder to do cleanly. But for a system with leakage, the alternative is fabricating a number.
5. Holdout / Counterfactual Logging
The one most teams should adopt and don’t.
The mechanic is straightforward: you permanently keep a small slice of your users (typically 1 to 5%) on a control experience that never receives any new features or model changes. This holdout acts as a frozen baseline against the rest of your population and measures the cumulative impact of every change you have shipped over time, not just the impact of whichever one is in the current launch window.
Spotify, Netflix, and Pinterest all run holdouts in production, and the reason they bother is feature drift. Consider a team building a RAG product that ships 20 changes in a year: a new embedding model, a new chunking strategy, a different reranker, a tweaked system prompt, two new tools added to the agent’s toolkit, a switch from one base LLM to another, a few retrieval-side guardrails, and so on. Each change gets declared a “+0.5% lift on retrieval quality” or “a 2% reduction in hallucination” in its own short A/B test. Add them all up and what should be a 10% lift in aggregate often turns out to be flat, or worse. Maybe nothing actually changed. Maybe several of those wins were noise that the team rounded up. Maybe one of them was secretly negative and the rest were compensating for it. The holdout is the only mechanism that can tell you which of those is true.
There is a darker version of the same problem, and it is especially common in AI systems. Most teams ship a model change, declare victory in the launch review, and never look at the metric again. Over time the change quietly decays. The embedding model drifts out of alignment with the corpus as content gets added, the reranker overfits to user behavior from six months ago, the agent’s tool list grows stale, the base LLM gets silently upgraded by the provider and your prompts no longer behave the same way, the user segment you optimized for shifts under you. Nobody notices because nobody is measuring against an unchanged baseline. Holdouts catch this too.
Use it whenever you ship features regularly, which is to say, always. A holdout is not really an experiment in the usual sense. It is infrastructure that your experimentation platform should support by default.
The trade-off is real. Between 1 and 5% of your users get a permanently degraded product experience. That is a genuine cost. The discipline is to be honest about it, monitor that group’s experience for outsized harm, and rotate the holdout cohort over long timescales if the cost starts to compound.
How they actually partition traffic
The five techniques look superficially alike from a distance. You split users somehow and compare. But the shape of the split is what makes each one work for the specific problem it was built to solve, and that shape is worth internalizing:
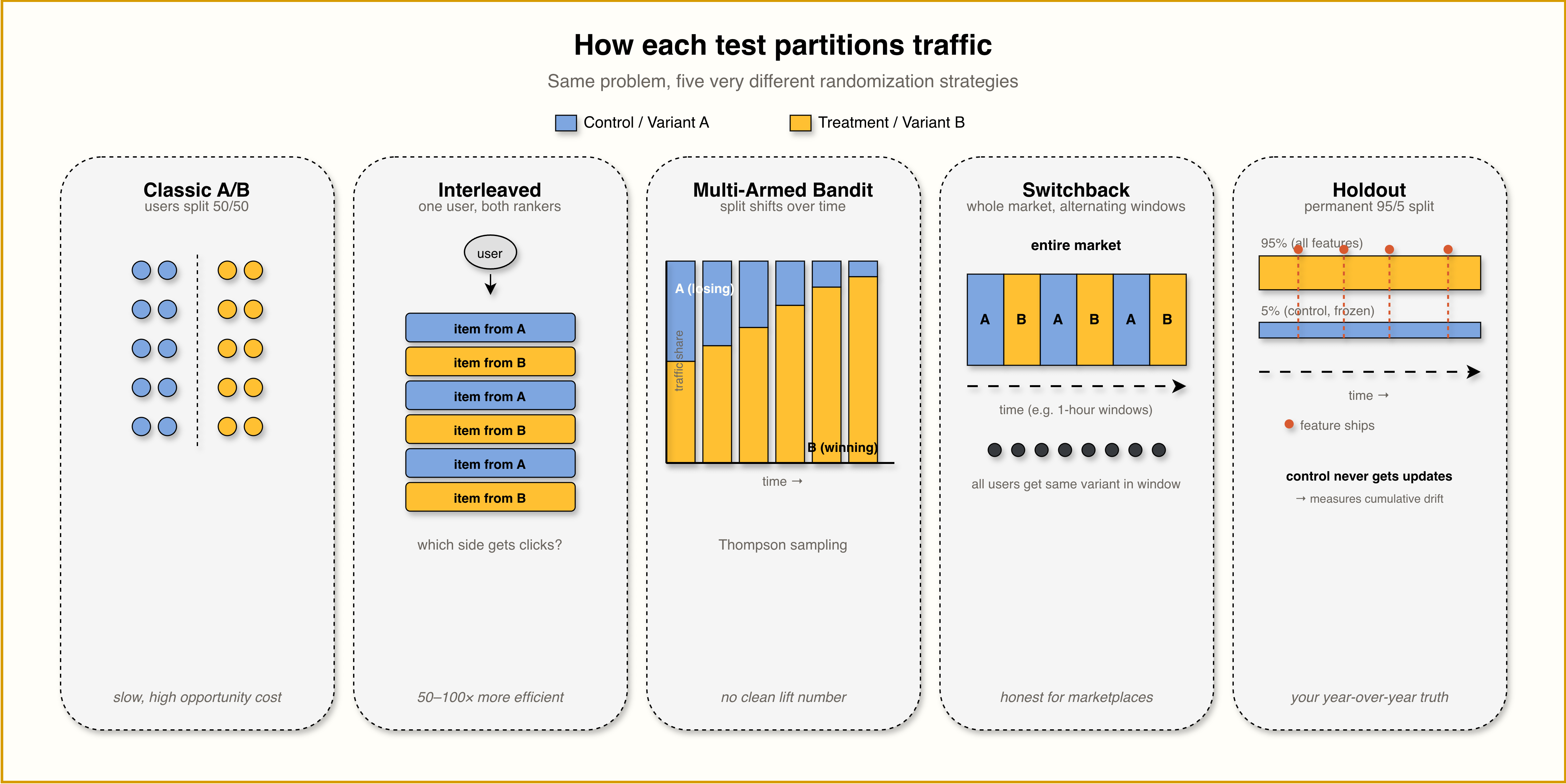
Classic A/B splits users in space, statically, for the duration of the test. Interleaved does not split users at all, it splits items within a single user’s view. Bandits split users in space, but the split moves over time as the algorithm learns which variant is winning. Switchback splits time across the entire population, so everyone is on the same variant within a given window. Holdouts split users in space and freeze that split forever, so the control group persists across every change you ship.
Each randomization shape exists to remove a specific source of confounding. That is the system-thinking lens worth taking away from this post. Once you start seeing A/B testing as a randomization-shape problem rather than a statistics problem, picking the right test stops feeling like a menu choice and starts feeling like a structural decision about your system.
Honorable mentions worth your homework
A few more techniques are worth knowing exist, even if I have not gone deep on them here:
CUPED. Variance reduction using pre-experiment data. Layered on top of any of the techniques above, it typically gives a 30 to 50% effective sample size boost for the same calendar time. Well-documented in Microsoft’s experimentation playbook.
Sequential testing (mSPRT and related approaches). The principled way to peek at your test early and stop it early without inflating your false-positive rate. The correct answer to the question “can I check the test daily without breaking the stats?”.
A/A tests. Run your experimentation platform against itself and expect to find no effect. If you find one anyway, your platform is broken. Most experimentation platforms have an A/A problem they do not know about.
Cluster and geo randomization. Useful when network effects make user-level randomization invalid but a switchback is not quite the right fit either. Geo-experiments at scale are how Meta and Google measure ad effects without contaminating treatment across friend graphs.
Each of these deserves its own deep dive.
The takeaway
Most engineers know A/B testing as one thing: split traffic, run a t-test, ship the winner. That is table stakes. The teams that ship faster than yours are running interleaved tests on their rankers and retrievers, bandits on their prompt and content variants, switchback on their marketplace and shared-resource systems, and a permanent holdout sitting underneath all of it.
When you can build a new model in an afternoon, the experiment design is what determines how often you actually get to ship one. Pick the right tool for the shape of your system, not the tool from your stats course.

If you enjoyed this read? do share it with your colleagues and team :)