

When to use - MCP vs API vs Function/Tool calling in your AI Agent
A Decision Framework for AI Engineers


Hi there 👋 ,
If you’ve been building AI agents or following the space, you’ve run into this exact confusion: should I use a direct API call, function/tool calling, or MCP?
The internet is full of takes. Some people treat MCP like the second coming. Others say it’s overengineered glue. And a growing crowd in 2026 says CLIs might beat both.
Here’s the thing. They’re all right, and they’re all wrong. Because the answer depends on where you are in your project, how many integrations you need, and what you’re optimizing for.
There's no shortage of content explaining what each of these patterns does. What's missing is a clear framework for choosing between them based on your actual constraints: project stage, integration count, team size, compliance needs. That's what this post is.
Let’s go.
First, Let’s Get the Definitions Straight
Before comparing anything, we need to agree on what we’re actually comparing. These three patterns get conflated constantly because they’re not three separate things. They’re layers that build on each other.
Pattern 1: Direct API Calls
This is the foundation. Your agent (or your code) makes HTTP requests directly to an external service. REST, GraphQL, gRPC, whatever. You write the endpoint, handle auth, parse the response, manage errors. The LLM has nothing to do with it. Your application code owns the entire flow.
When your backend needs to fetch a user profile from your database, it doesn’t need an LLM to decide that. It calls the endpoint directly.
Pattern 2: Function Calling / Tool Use

This is where the LLM enters the picture. OpenAI popularized this in mid-2023 with their Chat Completions API update. But here’s the mental model: tool calling is essentially wrapping an API into a structured schema that an LLM can understand and invoke.
You define a set of functions (tools) as JSON schemas with names, parameter types, and descriptions. You send them alongside your prompt. The model decides which function to invoke based on the user’s query. The model outputs structured JSON with the function name and arguments. Your application then executes the actual API call and feeds the result back.
The critical nuance: the LLM does not execute anything. It generates a structured request. Your code still makes the same API call you would have made in Pattern 1. Tool calling just adds an intelligent routing layer on top. The LLM becomes the decision-maker for which API to call and with what parameters.
Every major LLM provider supports this now, but each implements it slightly differently. OpenAI, Anthropic, Google all have their own schemas and invocation patterns. If you want to switch from GPT to Claude, you’re rewriting tool definitions. If you want to add the same tool to two different agents built on two different providers, you’re maintaining two separate implementations.
That fragmentation is exactly why MCP exists.
Pattern 3: MCP (Model Context Protocol)
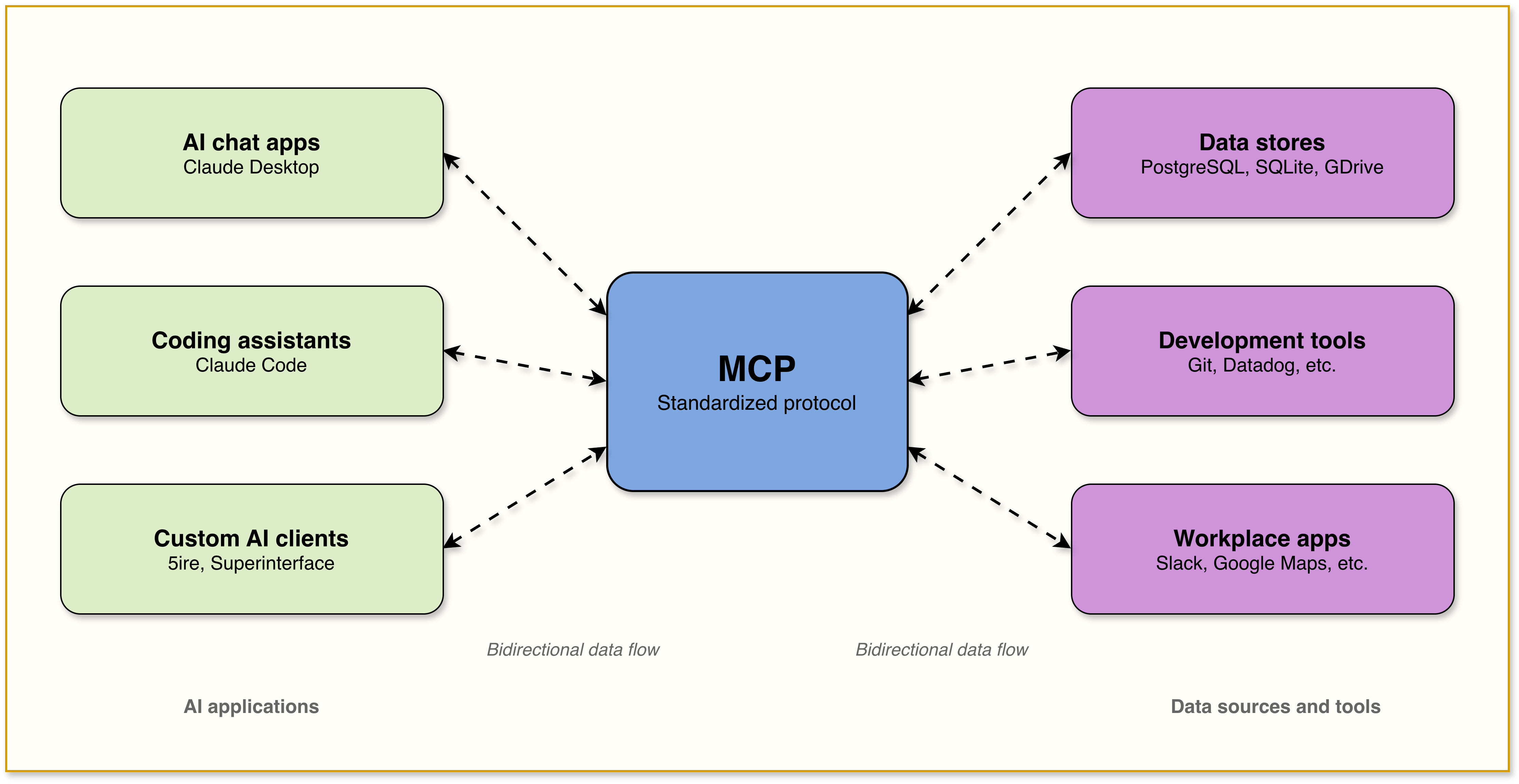
MCP is the standardization layer on top of tool calling. It doesn’t replace function calling. It standardizes it. Just as REST standardized web service communication and Docker standardized deployments, MCP standardizes how any AI model connects to any external tool.
Note: MCP can also stand on its own: an MCP server can be a self-contained service that does the work directly, without wrapping an existing API underneath.
Anthropic introduced MCP in November 2024 as an open standard. It uses a client-server architecture where MCP servers expose tools, resources, and prompts through a consistent interface. Any MCP-compatible client (Claude Desktop, Cursor, ChatGPT, your custom agent) can connect to any MCP server and discover available capabilities at runtime.
The three key things MCP adds on top of basic tool calling:
Dynamic discovery: With function calling, tools may be hardcoded into your prompt. With MCP, the agent queries the server at runtime to learn what’s available. New tools appear without code changes on the client side.
Model-agnostic portability: Build an MCP server once, and it works with Claude, GPT, Gemini, Llama, or any model that supports MCP. There is no more need of maintaining separate tool definitions per provider.
Credential isolation: The server handles auth and execution. The AI agent never touches your API keys. Credentials stay behind the server boundary.
How They Relate:
These three patterns often layer on top of each other. In the most common setup, they form a stack.
APIs provide the raw capability (an HTTP endpoint that does something).
Tool calling wraps that capability in a schema so an LLM can decide when and how to invoke it.
MCP standardizes that schema so any LLM can discover and call any tool, regardless of provider. Each layer builds on the one below it.
But MCP servers and tools don’t always wrap an existing API. An MCP server can be a self-contained service that does the work directly: reading files from disk, querying a database, running computations, processing data. In that case, the MCP server is the service.
There’s no REST endpoint underneath, no separate API to maintain. You’re building a small, purpose-built microservice that speaks MCP natively, and any compatible agent can connect to it.
This is worth understanding because it changes the design decision. You’re not always choosing between “direct API call vs. tool calling vs. MCP.” Sometimes the question is: should I build a traditional API and then wrap it, or should I build an MCP server from the start and skip the API layer entirely?
Bonus Pattern: CLIs
This is the contrarian take gaining serious traction in 2026. Instead of wrapping tools behind MCP or function schemas, you let the agent call CLI tools directly through the shell.
gh pr list, docker build, kubectl get pods.
LLMs were trained on enormous amounts of CLI documentation and usage, so they already know how to use these tools without reading any schema you provide.
Andrej Karpathy captured it in a February 2026 post: CLIs are exciting precisely because they are a “legacy” technology, which means AI agents can natively and easily use them.
Peter Steinberger, creator of OpenClaw (250K+ GitHub stars, one of the fastest-growing open-source projects in GitHub history), built his entire agent framework around this idea. OpenClaw does not use MCP in its core architecture, relying instead on a skills-and-CLI approach.
CLIs aren’t competing with MCP or function calling. They operate in a narrower lane: tools that already have mature command-line interfaces, where the model’s training data is the documentation. That lane is surprisingly wide (git, docker, kubectl, cloud provider CLIs, database CLIs), but it has edges. Custom internal tools, SaaS platforms without CLIs, anything requiring structured output that the CLI doesn’t provide cleanly, those still need the other patterns.


Free e-book alert!!! AWS just dropped a free 15-chapter book from data leaders at JPMorgan Chase, Bank of America, Siemens, Mercedes-Benz, etc. If you’re building and shipping agents in 2026, read this before your next architecture review.
How These Patterns Work Together in Practice
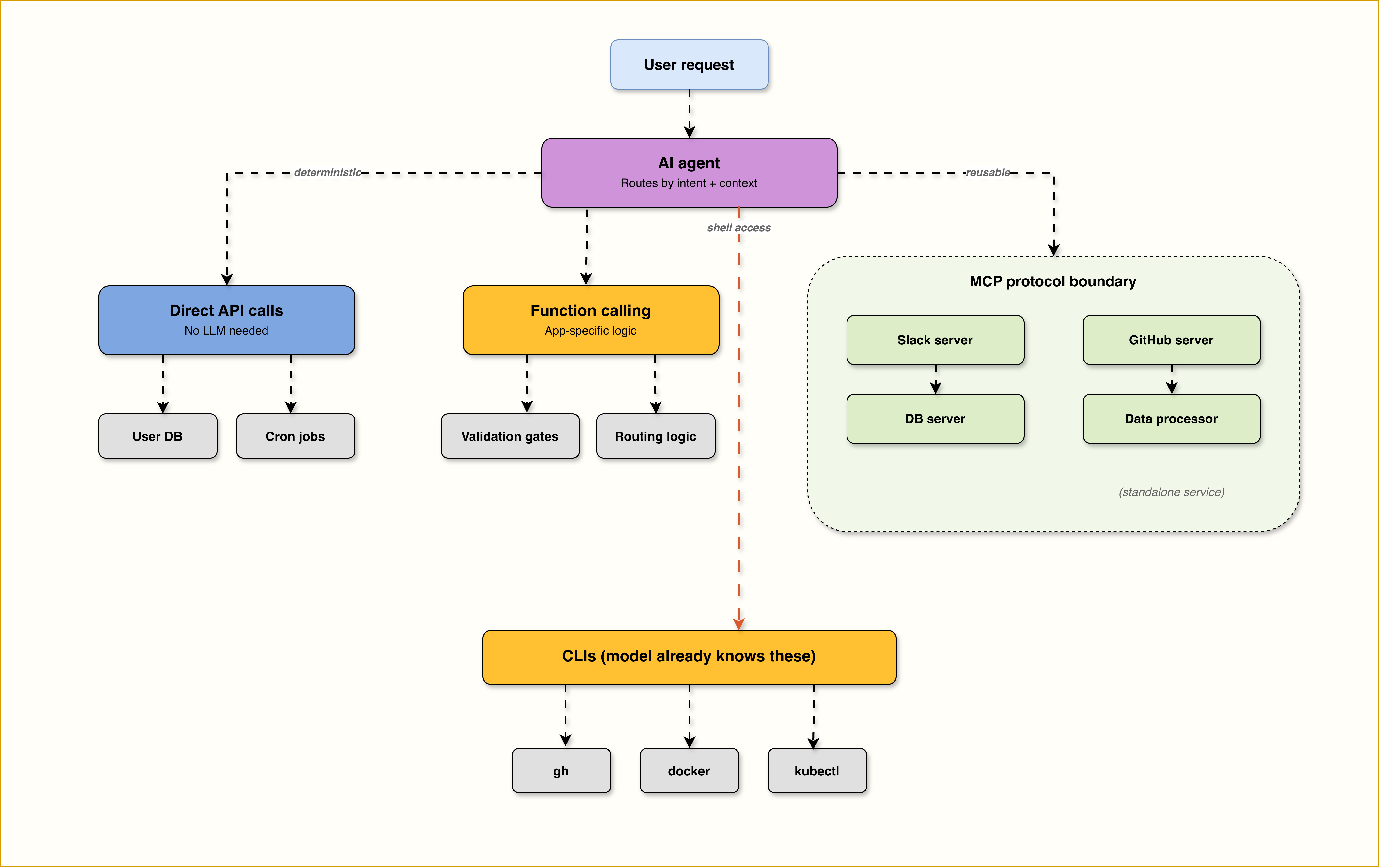
The framework below gives you a guided decision logic. But in practice, nobody picks just one pattern. In practice, a single agent might shell out to a CLI, call two MCP servers, run internal validation through function calling, and hit a direct API for a status check, all in one user request.
CLIs for tools the model already knows (git, docker, curl, gh).
Function calling for app-specific logic, validation gates, and routing decisions within a single agent.
MCP servers for reusable integrations shared across multiple agents or products (Slack, databases, ticketing systems, cloud services), or as standalone services that expose custom capabilities directly (data processing, internal tools, domain-specific computations).
Direct API calls for deterministic operations that don’t need LLM reasoning.
A Concrete Example: Same Task, Three Patterns
Let’s make this tangible. Imagine you want your AI agent to create a GitHub issue.
Pattern 1: Direct API Call Your code directly calls :
POST https://api.github.com/repos/{owner}/{repo}/issueswith a JSON body. No LLM involved. You hardcode when this happens (maybe after a test failure). You handle the Bearer token, the headers, the error codes. Simple, predictable, fast.
Pattern 2: Tool Calling You define a tool schema:
create_github_issue(repo: string, title: string, body: string, labels: list)You send this schema to the LLM alongside the user’s message. When the user says “file a bug for the login crash,” the model outputs:
{
"tool": "create_github_issue",
"args": {"repo": "myapp", "title": "Login crash on iOS", ...}
} Your code catches that, makes the same GitHub API call from Pattern 1, and sends the result back to the model.
The LLM decided what to do. Your code decided how to do it.
Pattern 3: MCP You connect your agent to the GitHub MCP server. The agent discovers that create_issue, list_pulls, search_code, and dozens of other tools exist. The user says “file a bug for the login crash.” The agent picks create_issue, the MCP server executes the API call with its own stored GitHub token, and returns the result. You didn’t write any GitHub-specific code on the client side. If tomorrow you want the same agent to also work with GitLab, you connect a GitLab MCP server. Zero changes to your agent code.
The tradeoff is clear: each pattern adds a layer of abstraction and a layer of capability. The question is whether you need that capability for your specific use case.
The Complexity Spectrum
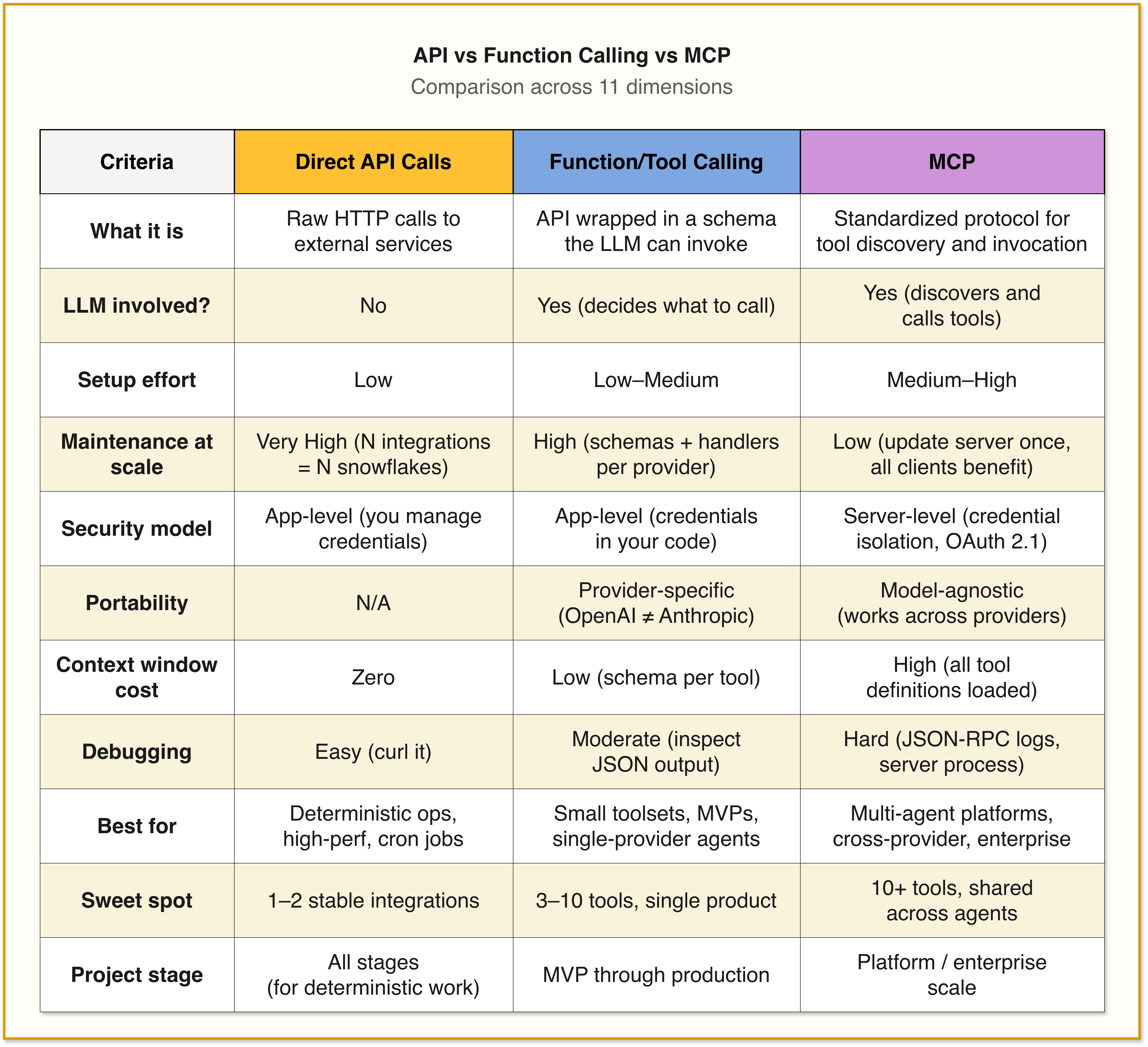
Here’s how these patterns stack up across the dimensions that actually matter in production.
1. Setup Complexity
Direct API Calls are the simplest to start with. You write an HTTP request, handle the response, done. No protocol overhead, no server to run, no schema to define. But this simplicity is front-loaded. The maintenance burden grows linearly with every new integration.
Function Calling/Tool use adds a layer. You need to define JSON schemas for every tool, handle the model’s structured output, execute the function, and feed results back. But it’s all in your application code. No external infrastructure needed. For 3-5 tools, this is manageable.
MCP requires the most upfront investment. You need an MCP server (build your own or configure an existing one), implement JSON-RPC 2.0 communication, and manage the connection between client and server. You’re running at least two separate processes. But once the infrastructure is in place, adding new tools becomes trivial. You add them to the server once, and every connected client picks them up.
2. Maintenance Burden
This is where the calculus flips.
Direct API Calls: Highest long-term maintenance. Every API change, every new auth flow, every rate limit update requires manual code changes. If you’re integrating with 10+ services, you’re maintaining 10+ custom integrations.
Function Calling/Tool use: Moderate maintenance. You’re managing a library of tool schemas plus the execution code for each. When an external API changes, you update the schema and the handler. But the schemas are tightly coupled to your application. If you support multiple LLM providers, you’re maintaining different schema formats for each.
MCP: Lowest maintenance at scale. You update the MCP server once, and every agent using it gets the update. The protocol handles auth, error responses, and tool discovery in a standardized way. The tradeoff is that you now have infrastructure to maintain (the MCP server itself), but that’s one piece of infrastructure versus N custom integrations.
3. Security Model
Direct API Calls: Credentials live in your application. You manage them directly. Full control, full responsibility.
Function Calling/Tool use: Same as direct API calls. Credentials, API keys, and access tokens live in your main app as environment variables or config files. When the LLM decides to call a function, your application uses these credentials directly. The model never sees them, but they’re all in one place.
MCP: Credential isolation is built into the architecture. Credentials live on the MCP server. The AI agent never sees raw API keys. The server enforces permission checks, and the client only receives the results. This is a genuine architectural advantage for handling sensitive data.
4. Performance and Token Cost
Direct API Calls: Fastest. No reasoning layer, no protocol overhead. A direct HTTP call with predictable latency.
Function Calling/Tool use: Adds the LLM reasoning step (the model decides what to call), but execution is still direct. The overhead is the inference time for tool selection. Tool definitions do consume input tokens, but for a small toolset this is negligible.
MCP: Adds protocol overhead on top of everything else. JSON-RPC communication, tool discovery, session management. For time-sensitive workflows like monitoring stock prices, IoT sensors, or real-time analytics, direct API calls still provide significantly more predictable performance.
The bigger concern with MCP is the context window tax. Every MCP tool definition gets loaded into the model’s context. GitHub’s MCP server alone can consume 40,000-55,000 tokens just for its tool definitions. A typical multi-server setup (GitHub + database + file system + Slack) can eat 75,000+ tokens in overhead alone. On a 200K context window, that’s over a third of your capacity gone before the agent does anything useful.
This is why the emerging best practice is aggressive curation. Don’t just auto-convert your OpenAPI spec into an MCP server. Abstract low-level endpoints into high-level, task-oriented tools. Fewer tools, better descriptions.
The Decision Framework: What to Use and When
Here’s the framework that maps each pattern to project stage, integration count, and primary constraint.
Stage 1: Proof of Concept / MVP
Use: Function Calling
You’re validating an idea. You have 2-5 tools. You need speed. Don’t introduce MCP infrastructure here. You don’t yet know which tools your agent actually needs or how users will interact with them.
Pay attention to which tools get used heavily during prototyping. That data will inform your architecture decisions later.
Stage 2: Single-Product Agent (Production)
Use: Function Calling + Direct API Calls
You’ve validated the concept. You’re shipping a product with 5-10 tools, a stable integration set, and endpoints you control. Function calling gives you full ownership of auth, execution, and error handling. When something breaks, you copy the curl command, run it, check the response. Debugging is straightforward.
Use direct API calls for any deterministic operation where no LLM reasoning is needed: fetching a user profile, checking an order status, running a scheduled export. If your backend can handle it in 5ms, don’t route it through an agent. MCP at this stage is typically overhead. You’re one team, one product, one model provider. The N×M problem doesn’t exist yet.
Stage 3: Multi-Agent / Multi-Product Platform
Use: MCP + Function Calling (Hybrid)
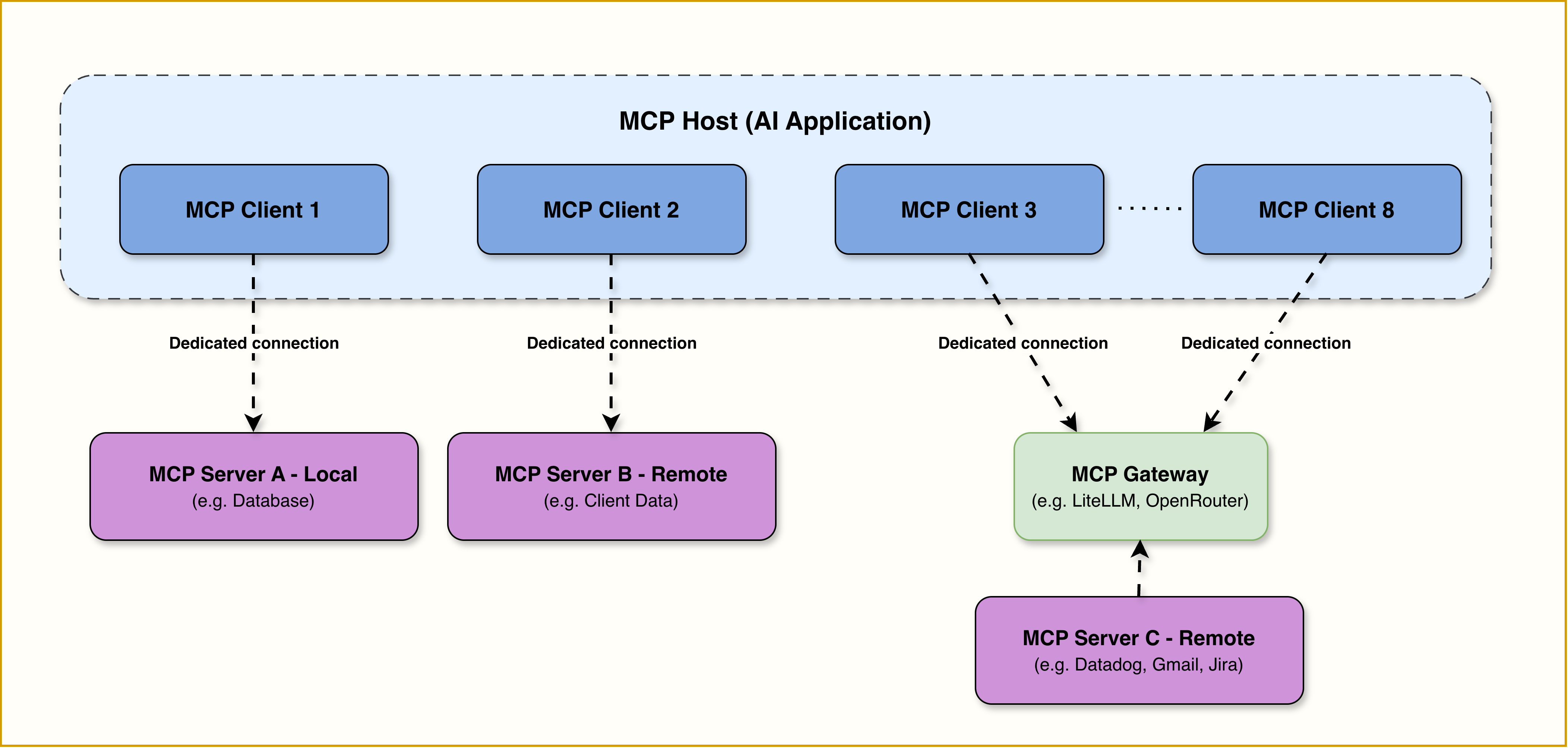
Here multiple agents or products need the same integrations. You’re supporting multiple LLM providers. The tool set is growing beyond what one team can maintain inline.
Build the Slack integration once as an MCP server, and every agent across your organization can use it. No duplicated credentials, no syncing tool definitions across codebases. Update the schema in one place, every connected client picks it up.
But keep function calling for app-specific logic: routing decisions, validation gates, business rules that only make sense inside one particular agent. MCP servers handle “what can I connect to,” function calling handles “what should this specific agent do.”
At enterprise scale, where you're serving hundreds of customers each with their own Salesforce, GitHub, or Gmail credentials, and SOC 2 / GDPR / HIPAA compliance is non-negotiable, add an MCP Gateway between your agents and MCP servers. The gateway centralizes authentication, authorization, auditing, and traffic management.
Common Mistakes Teams Make
Mistake 1: Using MCP for everything. MCP is powerful, but it’s not free. Every tool definition consumes context tokens. Every server adds infrastructure to maintain. If your agent only needs to call two APIs, function calling is simpler, cheaper, and easier to debug.
Mistake 2: Ignoring the context window tax. A typical multi-server MCP setup can consume 75,000+ tokens in tool definitions alone. On a 200K context window, that’s over a third of your capacity gone before the agent does anything useful. Be deliberate about which servers you connect. Cursor enforces a hard limit of 40 tools because quality degrades dramatically beyond that threshold.
Mistake 3: Wrapping every API endpoint as a separate tool. The emerging best practice for MCP servers: don’t auto-convert your OpenAPI spec one-to-one. Curate aggressively. Abstract low-level endpoints into high-level, task-oriented capabilities. An MCP server with 93 tools (like GitHub’s) is overwhelming for most models. Fewer, smarter tools are much better than many granular ones.
Mistake 4: Using an LLM when you don’t need one. If the operation is deterministic (fetching a user profile, checking an order status, running a cron job), don’t route it through an agent. Use a direct API call. The LLM adds latency, cost, and nondeterminism for zero benefit.
Mistake 5: Treating these as mutually exclusive choices. The title of this post says “vs” but the real answer is “and.” The best production systems use all of these patterns, each for what it’s good at. Function calling for the LLM reasoning loop. MCP for shared, reusable integrations. Direct API calls for deterministic operations. CLIs for developer tools. It’s a toolkit.
Mistake 6: Designing MCP tools like you’re writing an API for developers. Your API has 80 endpoints? That doesn’t mean your MCP server needs 80 tools. Models can’t browse your docs, can’t learn from past sessions, and can’t infer relationships between endpoints that seem obvious to you. Consolidate around user intent, write descriptions that explain when and why to use each tool (not just what it does), and make every response guide the model toward the correct next action. The gap between “technically works” and “works reliably in production” is almost entirely tool design.
The Bottom Line
Here’s the TL;DR decision tree:
Do you need LLM reasoning to decide what action to take?
No → Use direct API calls. Done.
Yes → Continue.
How many tools/integrations do you have?
1-5 → Use function calling. Ship fast, iterate.
5-20 → Consider MCP for shared integrations + function calling for app logic.
20+ → Use MCP servers (or a unified API platform) + an MCP gateway for governance.
Do multiple agents/products share the same integrations?
No → Function calling is fine.
Yes → MCP is the right abstraction.
Are you building a new capability from scratch (no existing API)?
Yes, and multiple agents will use it → Build it as an MCP server directly. Skip the API layer.
Yes, but only one agent needs it → Function calling with the logic inline is simpler.
Does a CLI already exist for this tool?
Yes → Try it first. Especially for git, docker, cloud CLIs, and dev tools.
Is the operation time-critical (sub-10ms)?
Yes → Direct API calls only. No LLM in the loop.
Just don’t go behind the technology because it’s hype in the market. Please think and apply to your use case.
I hope you found this look valuable and you have a bit more overview of when to apply each. Time to revisit your past decisions?
Until next time.

If you enjoyed this read? do share it with your colleagues and team :)