



The Search Foundation Every RAG System Needs
Mother of AI Project, Phase 1: Week 3


If retrieval is shaky, answers will be shaky. This week we make search solid before touching chunking or embeddings.
Hey there 👋,
Welcome to the lesson three of “The Mother of AI” - Zero to RAG series!
Quick recap:
A strong RAG system is a chain: infra → data → search → generation.
Weeks 1–2 gave us the plumbing and live data. Now we turn that data into something findable.
Week 1:

Week 2:

This week’s goals
The internet aka AI influencers loves to jump straight to vectors. We won't. We'll stand up a keyword-first retrieval layer that already answers a surprising share of queries - fast, cheap, explainable, then tee up hybrid for Week 4.
Ingest our corpus into OpenSearch.
Ship a BM25 retrieval path across title + text.
Add filters (category/date) and sorting (relevance/date).
Expose retrieval via our FastAPI endpoint.
Clarify when BM25 is enough and when to layer vectors/hybrid.
Deliverables
OpenSearch index + mappings (ready for BM25 now; vector field reserved for later).
Airflow DAG run that indexes documents end-to-end.
Keyword queries with filters & sorting working in OpenSearch.
FastAPI
/searchreturning top‑k results with proper error handling.Production-ready search that scales beyond your laptop.
What we built (high level)
Big picture: We took the cleaned papers from Week 2 and made them searchable. That means storing each paper in a search‑friendly structure (index), deciding which fields matter for matching (title/abstract/text), and exposing a clean API so any UI or agent can ask, "find me the top N relevant papers."
The shape is simple on purpose: a clean index, a predictable query, and a thin API. This is the retrieval baseline we'll measure hybrid against next week.
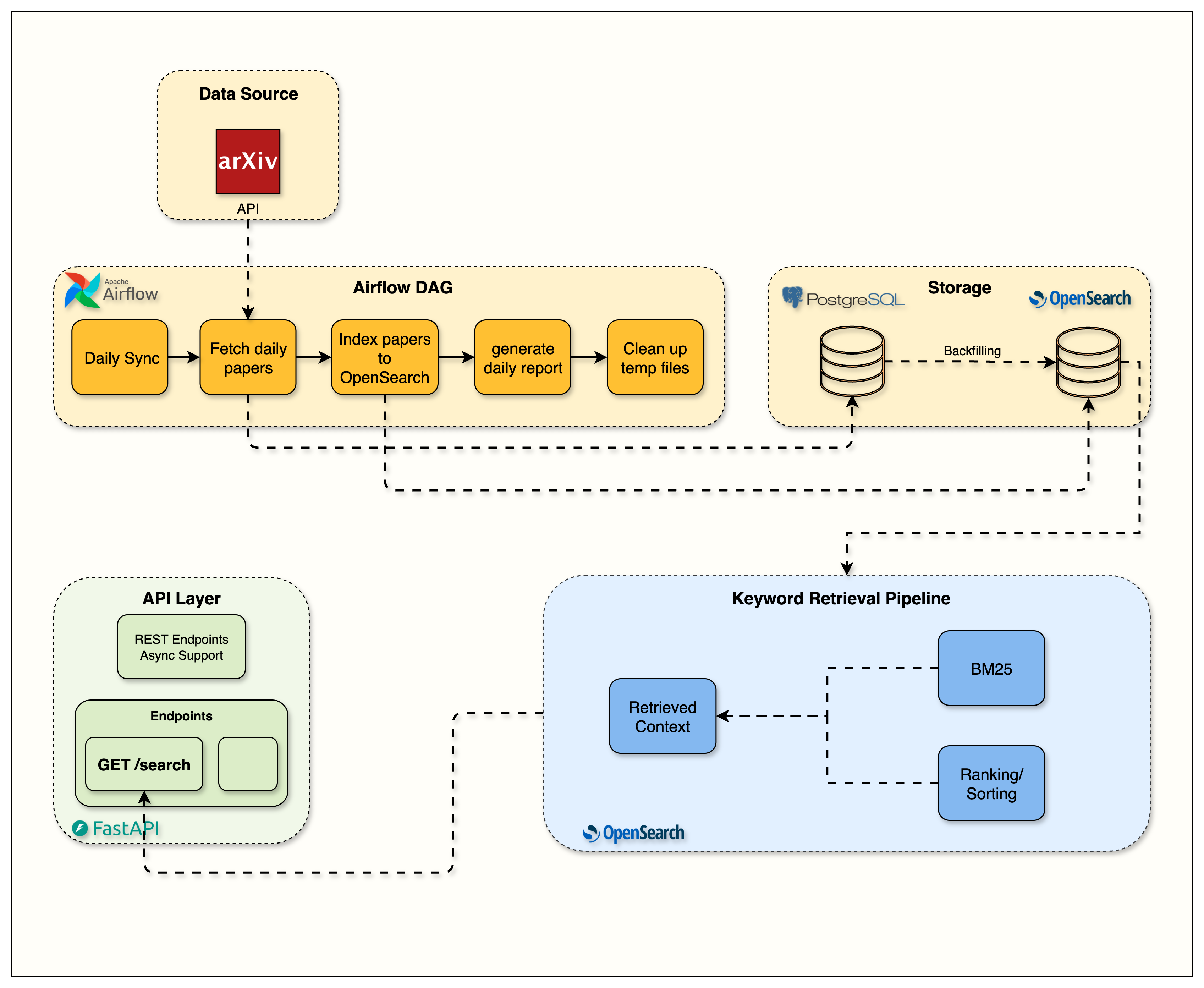
Data → OpenSearch: documents (title, abstract, full_text, authors, categories, published_date) under one index.
BM25‑first retrieval: multi‑field search over
title,abstract, andraw_textwith field boosts.Guardrails: category/date filters; result caps; sensible defaults.
API: a FastAPI route that forwards query → OpenSearch and returns normalized hits.
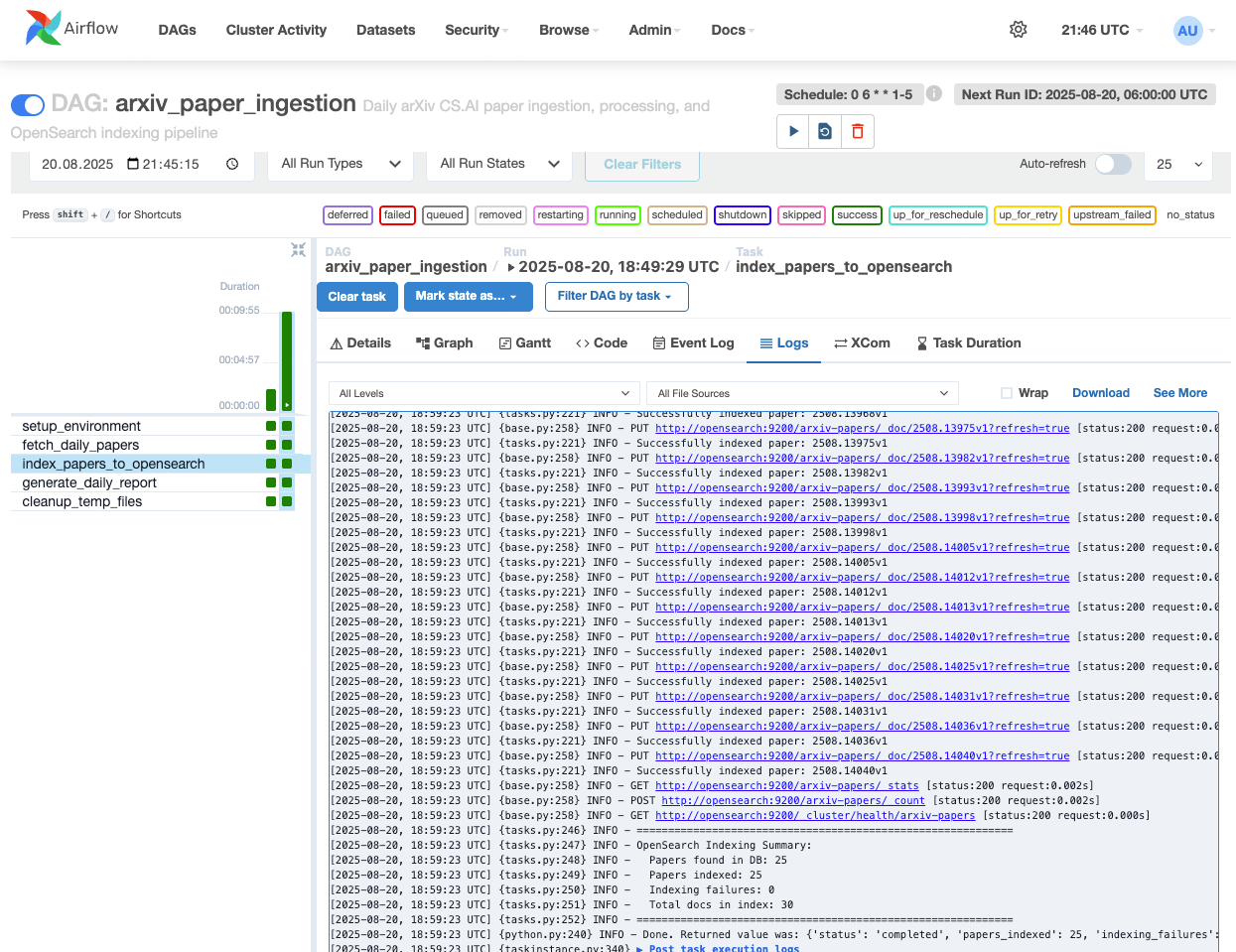
Ingestion via Airflow
Think of this as the conveyor belt from your data store into the search engine. Each run picks up new papers and pushes them into OpenSearch so the index never goes stale. You don't re‑build search by hand; the DAG keeps it refreshed automatically.
We extended our Week 2 DAG with OpenSearch indexing.
The service now handles the complete pipeline:
arXiv → PDF parsing → PostgreSQL → OpenSearch.
Modified DAG:
arxiv_paper_ingestion.pynow includes OpenSearch indexingIdempotent writes: papers are indexed by
arxiv_id, so re-runs don't create duplicatesError handling: individual paper failures don't break the entire batch
Metrics tracking: success/failure counts for monitoring
The service fetches from arXiv, parses PDFs with Docling, stores in PostgreSQL, and indexes to OpenSearch, all in one coordinated pipeline.
Index design (made simple)
An OpenSearch mapping is just a schema for the index, very similar to defining tables/columns in a database. Here we tell OpenSearch which fields are full‑text (use BM25), which are exact values (keywords for filters/sorts), and which are dates (for recency).
Our mapping in src/services/opensearch/index_config.py keeps it minimal but production-ready:

Essential fields:
arxiv_id: keyword (exact matching, primary key)title: text with custom analyzer + keyword subfield for sortingabstract: text for BM25 searchraw_text: full PDF content for comprehensive searchauthors: text for author name searchcategories: keyword array for filtering (cs.AI,cs.LG, etc.)published_date: date for recency sorting
Smart analyzers:
text_analyzer: custom tokenizer with lowercase, stop words, and snowball stemmingstandard_analyzer: standard tokenization with English stop words
This gives us BM25 search across content fields while preserving exact matching for filters and sorts.
How keyword search actually works
At a human level, keyword search asks: "Does this document contain the words I typed?"
Under the hood, here's what happens:
Index time: OpenSearch breaks each document into words ("tokens") and builds a reverse phone book for each word, it stores which documents contain it
Query time: When you search "neural networks", OpenSearch looks up documents containing "neural" and "networks"
Scoring: BM25 algorithm ranks these documents by relevance
How BM25 decides what's relevant:
Think of BM25 as a smart librarian who considers four things:
How often the words appear: A paper mentioning "transformer" 5 times is probably more about transformers than one mentioning it once. But there's a catch...
Diminishing returns: The difference between 1 and 5 mentions is huge. The difference between 45 and 50? Not so much. BM25 knows when to stop counting.
Document length fairness: A 50-page thesis mentioning "neural networks" twice might be less relevant than a 2-page abstract mentioning it twice. BM25 adjusts for this.
Word rarity: "Transformer" is more specific than "the" or "model". BM25 gives rare, specific terms more weight.
Real example: Search for "attention mechanism in transformers"
Paper A: 10-page paper, "attention" appears 8 times, "transformer" 5 times
Paper B: 100-page thesis, "attention" appears 20 times, "transformer" 2 times
Paper C: 5-page paper, title contains "Attention Mechanisms", no "transformer"
BM25 likely ranks: A > C > B. Why? Paper A has both terms in good proportion for its length. Paper C has "attention" in the title (we boost titles 3x). Paper B is too long relative to its term density.
Configuring search for better results
When search results aren't quite right, you have three knobs to turn: how text is processed (analyzers), how scores are calculated (BM25 parameters), and how queries are structured (query types). Let's make each one concrete.
Our analyzer choices
text_analyzer (for title, abstract, raw_text):
"text_analyzer": {
"type": "custom",
"tokenizer": "standard",
"filter": ["lowercase", "stop", "snowball"]
}
Why this works: Handles case variations, removes English stop words, applies light stemming. Conservative enough for technical content.
Our query builder strategy
In src/services/opensearch/query_builder.py, we implement smart multi-field search:
def __init__(self, query: str, fields: Optional[List[str]] = None):
# Multi-field search with intelligent boosting
self.fields = fields or ["title^3", "abstract^2", "authors^1"]What the complete query looks like:
When you search for "transformer attention", here's the actual OpenSearch query our builder creates:
{
"query": {
"multi_match": {
"query": "transformer attention",
"fields": ["title^3", "abstract^2", "authors^1"],
"type": "best_fields",
"operator": "or",
"fuzziness": "AUTO",
"prefix_length": 2
}
},
"size": 10,
"from": 0,
"_source": ["arxiv_id", "title", "authors", "abstract", "categories", "published_date", "pdf_url"]
}Field boost rationale:
Title^3: Paper titles get 3x weight (titles are dense with intent)
Abstract^2: Summaries get 2x weight (high-signal content)
Authors^1: Author names get base weight (sometimes you search by researcher)
Check OpenSearch documentation - https://docs.opensearch.org/latest/getting-started/search-data/
Verifying the index works
Before running queries, let's confirm papers are properly indexed.
Prerequisites:
Run the Airflow DAG first: Go to http://localhost:8080 and trigger
arxiv_paper_ingestionDAGWait for completion: The DAG should show all tasks green (about 5-10 minutes)
Open OpenSearch Dashboards: Navigate to http://localhost:5601
Go to Dev Tools: Click on the wrench icon in the left sidebar
Now let's verify everything is working.
Quick verification checklist:
1. Check document count:
GET /arxiv-papers/_countYou should see at least 10-15 documents (depending on your DAG configuration).
2. Verify index mapping:
GET /arxiv-papers/_mappingConfirm fields have correct types (text for title/abstract, keyword for categories).
3. Sample documents with match_all:
GET /arxiv-papers/_search
{
"query": { "match_all": {} },
"size": 3
}Expected response structure:
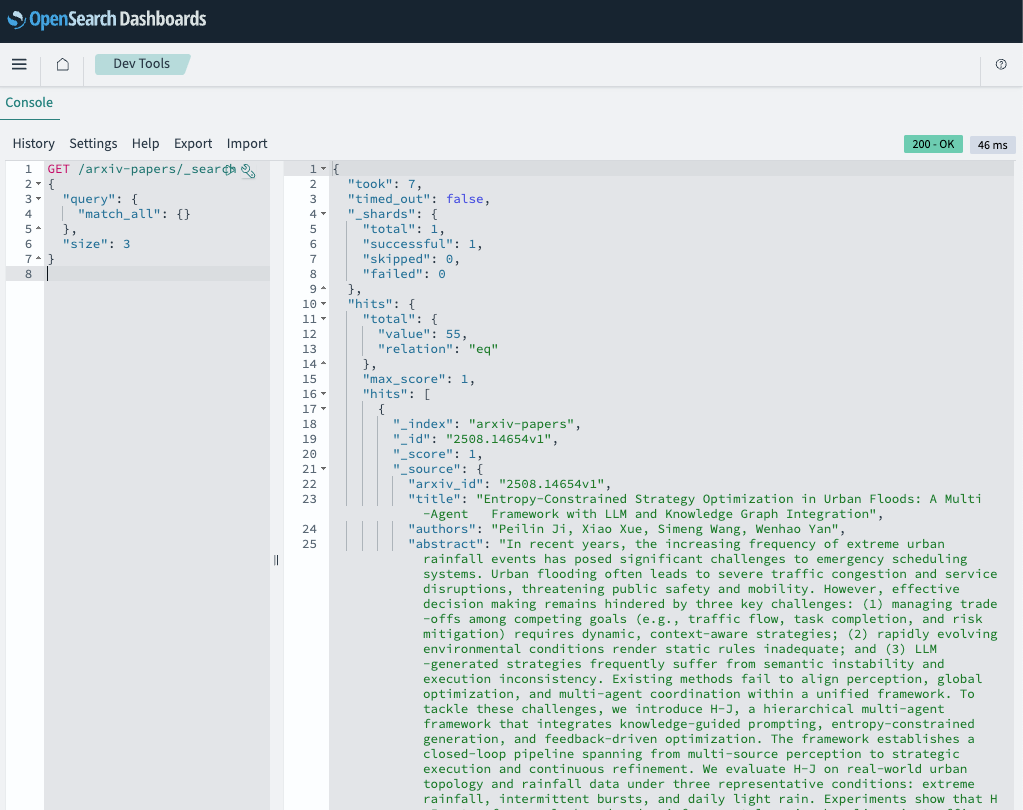
What to check:
✅ Papers have all fields populated (title, abstract, raw_text)
✅ Dates are properly formatted ISO strings
✅ Categories are arrays of keywords
✅ Each document has a score (1.0 for match_all)
Running basic keyword searches
Here's where BM25 shines. We search across multiple fields, boost important ones, and let relevance scoring do the work.
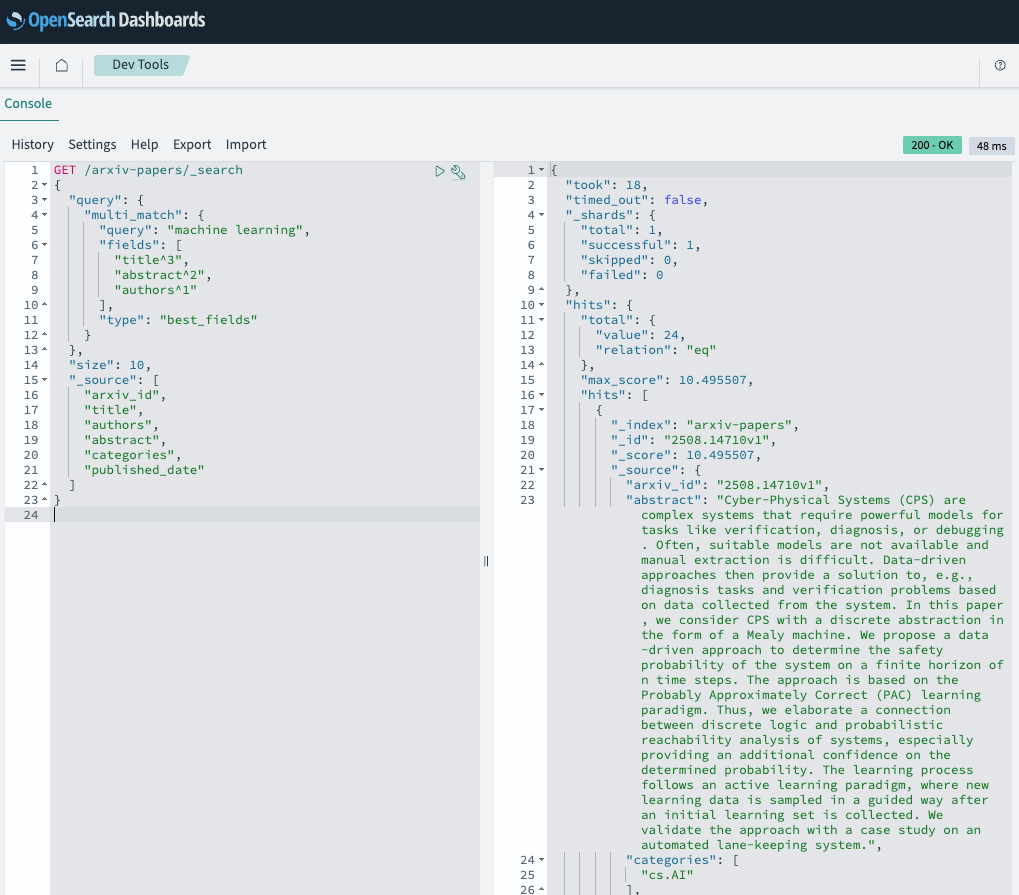
Simple search example:
# Search for "machine learning" across title and abstract
results = opensearch_client.search_papers(
query="machine learning",
size=10
)Behind the scenes, our query builder creates:
{
"query": {
"multi_match": {
"query": "machine learning",
"fields": ["title^3", "abstract^2", "authors^1"],
"type": "best_fields"
}
},
"size": 10,
"_source": ["arxiv_id", "title", "authors", "abstract", "categories", "published_date"],
}Why this works:
Papers with "machine learning" in the title score highest (3x boost)
Papers with terms in abstract score well (2x boost)
Author matches provide fallback relevance (1x boost)
BM25 naturally handles term frequency and document length
Building on Weeks 1-2
Our search layer builds on the solid foundation from previous weeks:
Week 1 infrastructure: OpenSearch runs in our Docker stack alongside PostgreSQL and Airflow
Week 2 data pipeline: Clean, structured papers flow automatically from arXiv to search index
Contracts first: Pydantic schemas ensure consistent data shapes across the pipeline
Observability: FastAPI provides automatic API docs; OpenSearch has built-in monitoring
The compound effect: Because we built proper abstractions in Weeks 1-2, adding search was mostly configuration, not complex integration work.
Adding filters and sorting
Users often imply constraints without saying them - domain, recency, author. Filters capture those constraints explicitly, and sorting aligns results with user intent.
Category filtering:
# Find AI papers only
results = opensearch_client.search_papers(
query="transformer",
categories=["cs.AI"]
)Date sorting:
# Latest papers first
results = opensearch_client.search_papers(
query="*", # match all
latest_papers=True # sort by publication date
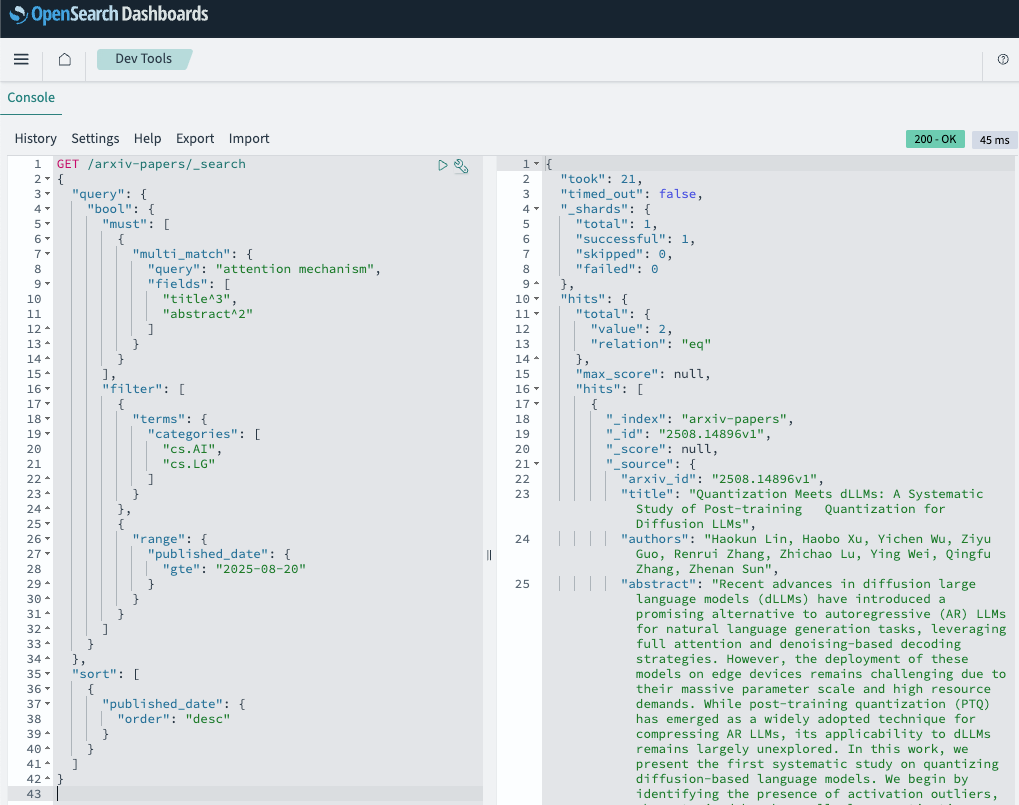
)Combined filtering:
{
"query": {
"bool": {
"must": [
{
"multi_match": {
"query": "attention mechanism",
"fields": [
"title^3",
"abstract^2"
]
}
}
],
"filter": [
{
"terms": {
"categories": [
"cs.AI",
"cs.LG"
]
}
},
{
"range": {
"published_date": {
"gte": "2025-08-20"
}
}
}
]
}
},
"sort": [
{
"published_date": {
"order": "desc"
}
}
]
}
The search API endpoint
Instead of every client speaking OpenSearch directly, we provide a single, stable endpoint. This keeps UIs simple and gives us one place to evolve retrieval logic.
Our /search endpoint in src/routers/search.py:
@router.post("/", response_model=SearchResponse)
async def search_papers(
request: SearchRequest,
opensearch_client: OpenSearchDep
) -> SearchResponse:
Request schema:
class SearchRequest(BaseModel):
query: str
size: int = 10
from_: int = Field(default=0, alias="from")
categories: Optional[List[str]] = None
latest_papers: bool = False
Response schema:
class SearchResponse(BaseModel):
query: str
total: int
hits: List[SearchHit]
error: Optional[str] = None
Production features:
Health checks: Verify OpenSearch before processing
Error handling: Graceful degradation with proper HTTP status codes
Validation: Pydantic ensures clean inputs/outputs
Pagination:
from_andsizefor result paging
When to use different retrieval methods
Not every question deserves the same retrieval path.
Don’t just start with vector search! Start simple, watch results, and layer complexity only where it pays off.
Query intent taxonomy:
1) Intent classification - based retrieval
When: Your corpus spans many domains (HR, Engineering, Legal, etc.)
How:
Tag documents with categories during ingestion
Use simple classification (or LLM) to predict user intent
Filter search to relevant category
Run BM25 within that subset
Example: "What's our remote work policy?" → classify as HR → search only HR documents
2) BM25 (keyword) retrieval ← Our Week 3 focus
When: Users search with specific terms, technical jargon, exact phrases
Strengths:
Fast (~15-50ms for 10,000+ docs)
Interpretable (you see exactly why papers matched)
No expensive embedding models
Works great for technical content
Great for: Paper titles, specific algorithms, author names, exact concepts
3) Dense vector similarity (semantic)
When: Users paraphrase, use synonyms, or describe concepts rather than naming them
Example:
User asks: "How to make models smaller?"
Vectors find: papers about "model compression," "pruning," "quantization"
BM25 might miss these without exact keywords
4) Hybrid (next week!)
The production sweet spot: Combine BM25 precision with vector recall
Common patterns:
BM25 for initial filtering → vectors for reranking
Weighted score fusion (0.6 × BM25 + 0.4 × vector similarity)
Cascade: try BM25 first, fall back to vectors if low results
Debugging common search problems
If results feel wrong, it's rarely "search is broken." Usually it's tokenization, overly strict queries, or configuration issues.
Common issues and fixes:
No results returned:
Check if index exists:
GET /arxiv-papers/_countVerify query syntax with
_validate/queryTry simpler query (single term, no filters)
Wrong results ranking:
Examine
_scorevalues in resultsUse
explain: trueto see BM25 scoring breakdownCheck field boosts are working (
title^3vsabstract^2)
Analyzer problems:
Test tokenization:
GET /_analyzewith your analyzerVerify stemming isn't over-aggressive for technical terms
Check case sensitivity matches expectations
Filter confusion:
Filters don't affect
_score, only candidate setDate filters: watch timezone differences
Category filters: ensure exact term matching
Performance issues:
Monitor query latency in OpenSearch
Check index segment count and merging
Consider pagination instead of large result windows
Code and resources
Code references:
src/services/opensearch/client.py
→ OpenSearch integration and search methodssrc/services/opensearch/query_builder.py
→ BM25 query construction with filterssrc/routers/search.py
→ FastAPI search endpointairflow/dags/arxiv_paper_ingestion.py
→ Extended DAG with OpenSearch indexingnotebooks/week3/week3_opensearch.ipynb
→ Interactive tutorial and examples
Resources:
GitHub: Complete Week 3 implementation
OpenSearch docs: Getting started guide
BM25 deep dive: Understanding the algorithm
Previous weeks:
What's next (Week 4)
Next week we'll introduce chunking and embeddings, then fuse BM25 + vectors for hybrid search. Our Week 3 BM25 baseline gives us a clear benchmark to measure improvements against.
Week 4 preview:
Document chunking strategies for long papers
Vector embeddings with sentence transformers
Hybrid search with score fusion
The goal: Build search that understands both what users say (BM25) and what they mean (vectors).
Follow Along: This is Week 3 of 6 in our Zero to RAG series. Every Thursday, we release new content, code, and notebooks.
Let’s go 💪
Just implemented BM25 + Vector Search. You can check it out here - https://github.com/raunaqness/production-rag/blob/week-3-raunaq-implement-vectors/WEEK4_IMPLEMENTATION_GUIDE.md
This was such a good learning exercise!
Some issues I found going through this why you might wanna update in the blog.
1. Delete and rebuild "rag-airflow" and "rag-api" services. I was getting DAG Import errors due to come missing python dependency. Rebuilding the image and container fixed it.
2. Remove the last comma in the query
{
"query": {
"multi_match": {
"query": "machine learning",
"fields": ["title^3", "abstract^2", "authors^1"],
"type": "best_fields"
}
},
"size": 10,
"_source": ["arxiv_id", "title", "authors", "abstract", "categories", "published_date"],
}