

Chunking strategies and Hybrid RAG system
Mother of AI Project, Phase 1: Week 4


Hey there 👋,
Welcome to lesson four of "The Mother of AI" - Zero to RAG series!
Quick recap:
A strong RAG system is a chain: infra → data → search → generation.
Weeks 1–3 gave us solid infrastructure, live data pipeline, and BM25 keyword search. Now we enhance that foundation with intelligent document chunking and hybrid search that combines the precision of BM25 with the semantic understanding of vectors.
Week 1: The Infrastructure That Powers RAG Systems
Week 2: Bringing Your RAG System to Life - The Data Pipeline
Week 3: The Search Foundation Every RAG System Needs
This week's goals
Most teams jump straight to "just chunk by 512 tokens and add embeddings." We won't. We'll implement section-aware chunking that respects document structure, then layer semantic search on top of our proven BM25 foundation.
Build section-based chunking that preserves document structure and context
Implement production-grade embeddings using Jina AI for semantic understanding
Create hybrid search combining BM25 + vector similarity with RRF fusion
Ship unified search API supporting multiple search modes from one endpoint
Benchmark performance across BM25, vector, and hybrid approaches
Deliverables
Section-aware text chunker handling documents from 1K to 100K+ words intelligently
Unified OpenSearch index supporting BM25, vector, and hybrid search from single schema
Production embedding pipeline with Jina AI integration and graceful fallbacks
Hybrid RRF search combining keyword precision with semantic understanding
FastAPI endpoints for all search modes with comprehensive error handling
Big picture: We took the searchable papers from Week 3 and made them semantically searchable. That means breaking long documents into coherent chunks, understanding what users mean (not just what they type), and combining the best of both keyword and semantic matching.
The architecture is intentionally layered: solid BM25 foundation, intelligent chunking strategy, semantic vectors on top, and hybrid fusion that gets the best of all worlds.
What we built (high level)
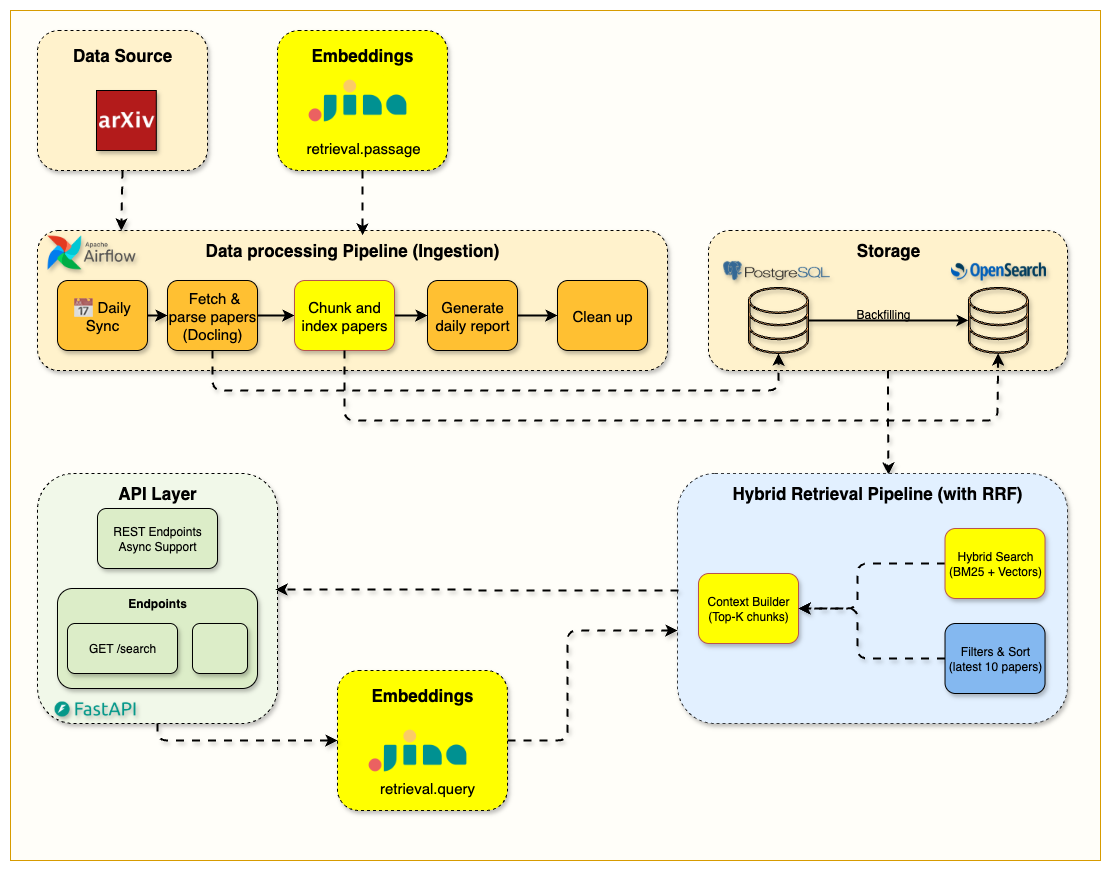
Section-based chunking: Documents → intelligent segmentation → context-aware chunks with 100-word overlaps
Unified index architecture: Single OpenSearch index supporting BM25, vector, and hybrid search modes
Production embeddings: Jina AI 1024-dimensional vectors with automatic generation and fallback handling
RRF hybrid search: Reciprocal Rank Fusion combining BM25 precision with semantic recall
Multi-mode API: Single endpoint supporting different search strategies based on use case
The chunking strategy that actually works
Think of this as the foundation that makes everything else possible. If you chunk documents poorly, even the best embeddings won't help you find relevant content. Our approach respects document structure while ensuring optimal chunk sizes.
Here you can utilize different chunking strategies:
We implemented a hybrid section-based strategy in src/services/indexing/text_chunker.py:
NOTE: You can google and you will find 10s of chunking strategies, but often they are highly dependent on your data structure. We have observed that the easiest approach works the best!
The algorithm:
Small sections (< 100 words): Combine with adjacent sections to reach minimum viable size
Perfect sections (100-800 words): Use as single chunks with paper title + abstract header
Large sections (> 800 words): Split using traditional overlapping word-based chunking
No sections available: Fallback to paragraph-based chunking with smart boundaries
Why this works:
Semantic coherence: Chunks follow natural document structure (Introduction, Methods, Results)
Context preservation: Each chunk includes paper title + abstract for context - making it more contextual aware
Optimal sizing: Target 600 words with 100-word overlaps prevents information loss
Flexible handling: Adapts to documents with or without structured sections
# Example: Chunking a 15,000-word research paper
chunker = TextChunker(
chunk_size=600, # Target words per chunk
overlap_size=100, # Overlap between chunks
min_chunk_size=100 # Minimum viable chunk
)
chunks = chunker.chunk_paper(
title="Transformer Neural Networks for Language Understanding",
abstract="Recent advances in attention mechanisms...",
full_text=full_paper_text,
sections=parsed_sections_dict # From Docling PDF parsing
)
# Result: 18 coherent chunks, each with context headerReal example: A typical ML paper gets chunked like this:
Chunk 1: Title + Abstract + Introduction (578 words)
Chunk 2: Title + Abstract + Related Work (602 words, 100-word overlap)
Chunk 3: Title + Abstract + Methods (Part 1) (587 words, 100-word overlap)
Chunk 4: Title + Abstract + Methods (Part 2) (614 words, 100-word overlap)
Each chunk is self-contained but maintains context through overlaps and header information.
Embeddings that work in production
The internet loves to debate embedding models. We picked Jina AI v3 because it's optimized for retrieval, handles academic content well, and provides 1024 dimensions that balance quality with performance.
And most important too easy to set it up!
You can just get the API key without signing up here - https://jina.ai/embeddings/
Our embedding service in src/services/embeddings/factory.py handles:
Production features:
Automatic generation: Query embeddings generated on-demand for hybrid search
Graceful fallback: Hybrid search falls back to BM25 if embeddings fail
Rate limiting: Respects Jina API limits with proper error handling
Batch processing: Efficient bulk embedding generation during indexing
The embedding pipeline:
# 1. Index time: Generate embeddings for all chunks
embeddings_service = make_embeddings_service()
chunk_embeddings = await embeddings_service.embed_chunks([chunk.text for chunk in chunks])
# 2. Query time: Generate query embedding automatically
query_embedding = await embeddings_service.embed_query("transformer attention mechanisms")
# 3. Vector search: Find semantically similar chunks
similar_chunks = opensearch_client.search_vector(
query_embedding=query_embedding,
size=10
)Performance characteristics (based on limited documents):
Embedding generation: ~200ms for typical queries
Vector search: ~100ms for 10 results across 1000+ chunks
Total hybrid search: ~400ms including BM25 + fusion
(Hybrid search scales very well for millions of documents)
Hybrid search with RRF fusion
Here's where it gets interesting. Instead of choosing between keyword search OR semantic search, we combine both using Reciprocal Rank Fusion (RRF).
RRF ranks documents by performing the following steps:
Sort documents by score: Each query method sorts documents by score on every shard.
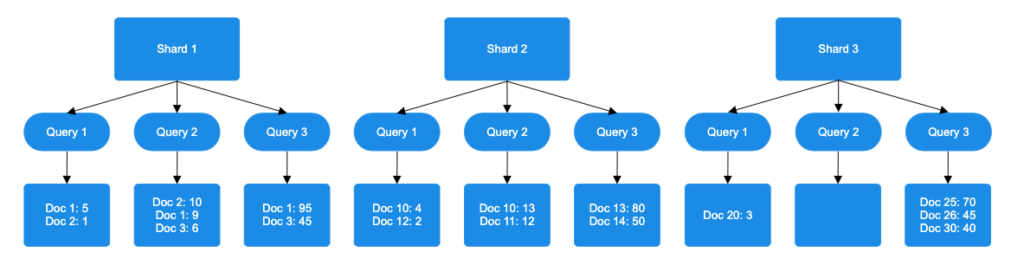
Assign rank positions: Documents are ranked based on score for each query.
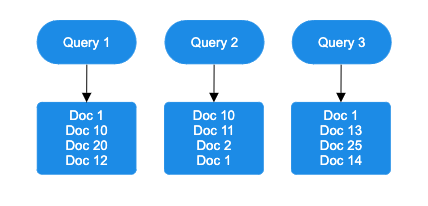
Apply the RRF formula: The RRF score is computed using the following formula:
rankScore(document_i) = sum((1/(k + query_1_rank), (1/(k + query_2_rank), ..., (1/(k + query_j_rank)))In this formula, k is a rank constant, and query_j_rank represents the ranking of a document in a particular query method. The example in the following diagram applies this formula using the default rank constant of 60.
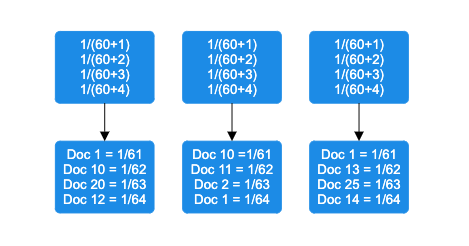
Add rank contributions: Rank calculations are combined, and documents are sorted by decreasing rank score.
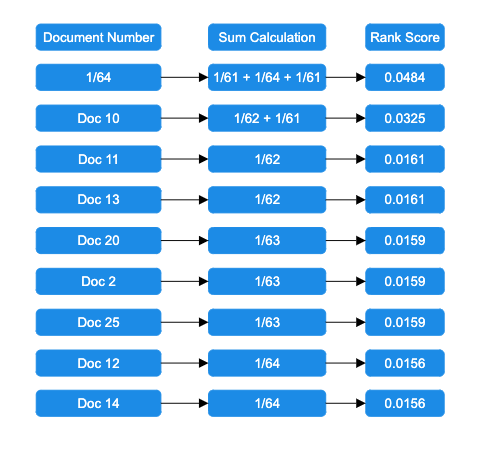
Return the top results: The highest-ranked documents are retrieved based on the query size.
Image credits: https://opensearch.org/blog/introducing-reciprocal-rank-fusion-hybrid-search/
Real example: Search for "attention mechanism in transformers"
BM25 results:
Paper mentioning "attention mechanism" 5 times (exact keyword match)
Paper titled "Transformer Attention Models" (high title relevance)
Paper discussing "self-attention" mechanisms (partial match)
Vector results:
Paper about "multi-head attention" (semantically similar)
Paper on "query-key-value attention" (concept similarity)
Paper discussing "attention patterns in neural networks"
Hybrid RRF results:
Paper with both exact keywords AND semantic relevance (best of both)
High-quality semantic matches that BM25 missed
Good keyword matches validated by semantic similarity
Building on weeks 1-3
Our hybrid search system builds seamlessly on previous foundations:
Week 1 infrastructure: OpenSearch container ready for vectors + BM25
Week 2 data pipeline: Clean, parsed papers with structured sections flow automatically
Week 3 search foundation: Proven BM25 implementation becomes one component of hybrid system
Unified evolution: Same endpoints, same workflows, enhanced with semantic understanding
The compound effect: Because we built proper abstractions in Weeks 1-3, adding hybrid search was mostly configuration and smart algorithms, not complex integration work.
The unified search API
Instead of separate endpoints for different search modes, we provide one endpoint that handles everything. This keeps client code simple and gives us flexibility to optimize behind the scenes.
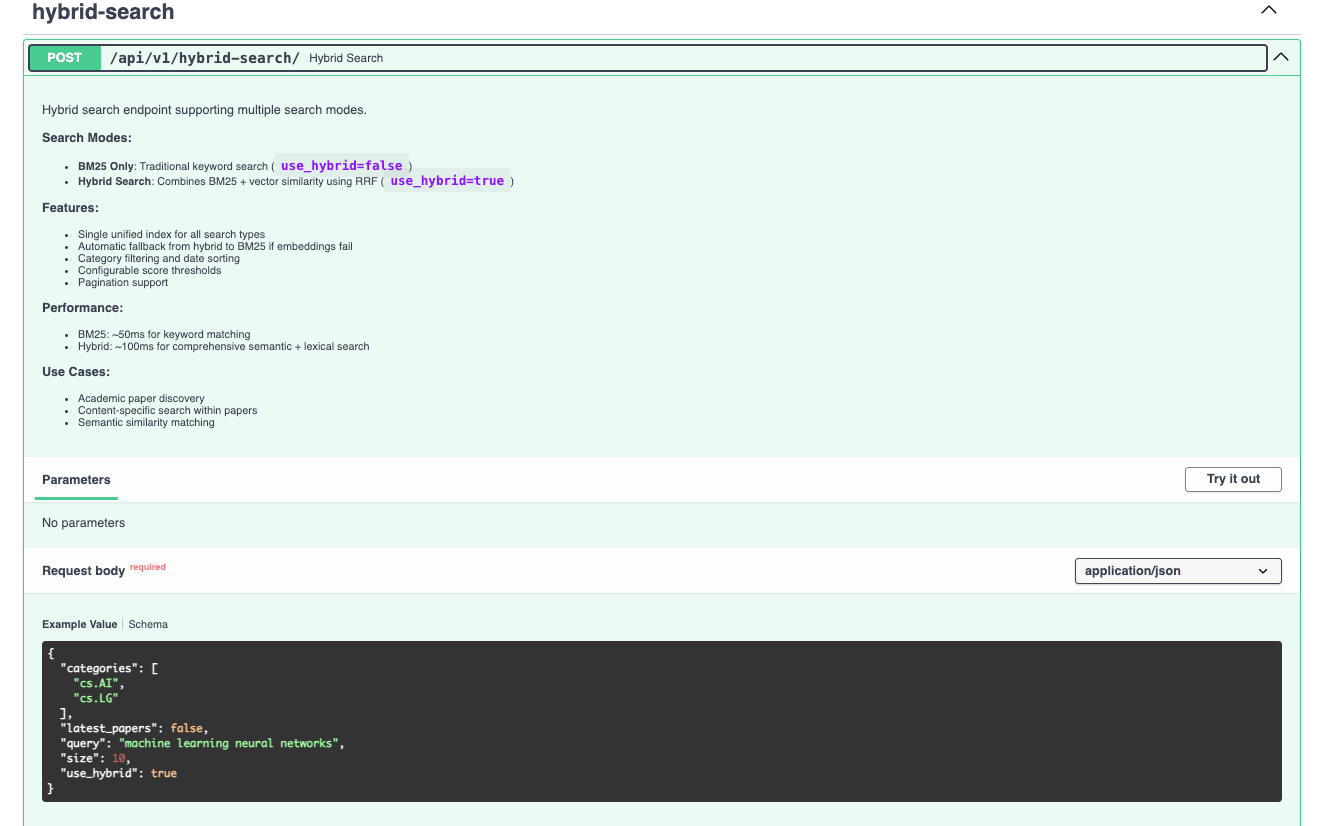
Our /hybrid-search endpoint in src/routers/hybrid_search.py:
@router.post("/", response_model=SearchResponse)
async def hybrid_search(
request: HybridSearchRequest,
opensearch_client: OpenSearchDep,
embeddings_service: EmbeddingsDep
) -> SearchResponse:
Request options:
{
"query": "transformer neural networks",
"use_hybrid": true, // Enable semantic search
"size": 10, // Results per page
"from": 0, // Pagination offset
"categories": ["cs.AI"], // Filter by arXiv category
"latest_papers": false, // Sort by recency
"min_score": 0.0 // Score threshold
}
Response format:
{
"query": "transformer neural networks",
"total": 23,
"hits": [
{
"arxiv_id": "2508.18563v1",
"title": "Attention Mechanisms in Modern NLP",
"authors": "Smith, J. et al.",
"abstract": "We present a comprehensive study...",
"score": 0.8942,
"chunk_text": "The transformer architecture revolutionized...",
"chunk_id": "uuid-chunk-1",
"section_name": "Introduction"
}
],
"search_mode": "hybrid", // Indicates which search was used
"size": 10,
"from": 0
}
Production features:
Health checks: Verify OpenSearch and embedding service before processing
Automatic fallback: Hybrid → BM25 if embeddings unavailable
Error handling: Graceful degradation with proper HTTP status codes
Validation: Pydantic ensures clean inputs/outputs
Monitoring: Comprehensive logging for search analytics
When to use different search modes
Not every query needs semantic search. Here's when to use what:
Search mode taxonomy:
BM25 Only (use_hybrid: false):
When: Specific terms, exact phrases, author names, paper IDs
Speed: ~50ms, highest throughput
Use case: "papers by Yoshua Bengio", "BERT model architecture"
Hybrid Search (use_hybrid: true):
When: Conceptual queries, paraphrased questions, exploratory search
Speed: ~400ms, comprehensive results
Use case: "how to make neural networks more efficient", "latest advances in computer vision"
Production sweet spot: Start with BM25 for fast results, upgrade to hybrid for complex queries based on user feedback and query patterns.
Code and resources
📓 Interactive Tutorial: notebooks/week4/week4_hybrid_search.ipynb
Full walkthrough with working code examples
Performance comparisons and benchmarks
Troubleshooting guide and best practices
📁 Key Files:
src/services/indexing/text_chunker.py- Section-based chunkingsrc/services/opensearch/client.py- Unified search with RRFsrc/routers/hybrid_search.py- Production API endpointsrc/services/embeddings/- Jina AI integration
📚 Documentation:
Week 4 README:
notebooks/week4/README.mdGitHub repository: Complete Week 4 implementation
Previous weeks:
Verifying everything works
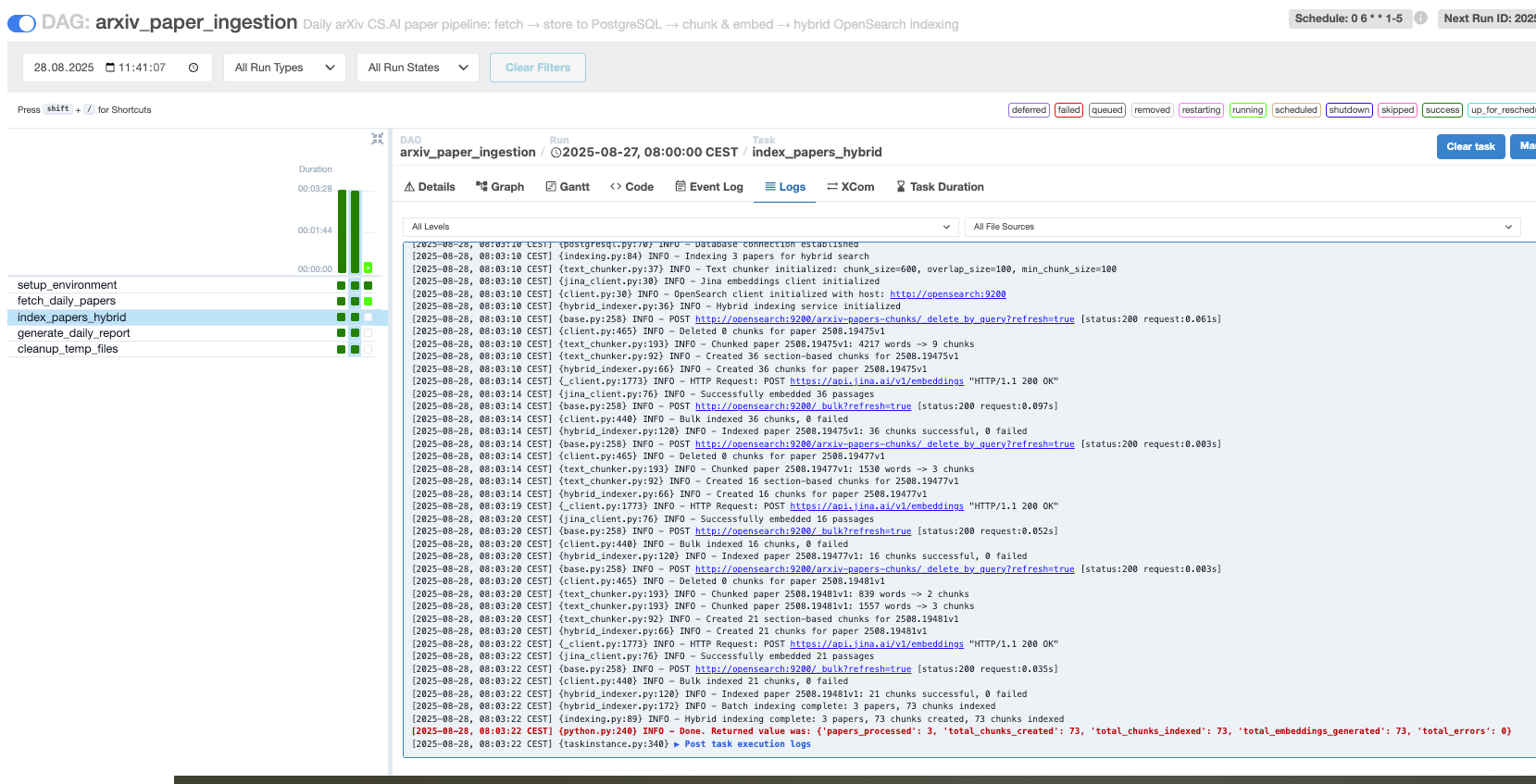
Before running searches, let's confirm the system is properly set up:
Prerequisites:
Start services:
docker compose up --build -dVerify health: Check all containers are running
Set Jina API key:
JINA_API_KEY=your_key_herein.env(get it here for free - https://jina.ai/embeddings/)Run ingestion: Trigger Airflow DAG to populate index
Testing the implementation
Want to see all this in action?
The Week 4 notebook provides comprehensive testing and verification:
# Launch the interactive tutorial
uv run jupyter notebook notebooks/week4/week4_hybrid_search.ipynbThe notebook includes:
Complete setup verification with health checks
Step-by-step testing of BM25, vector, and hybrid search modes
Performance comparisons across different query types
Troubleshooting guide for common issues
Real examples with actual arXiv papers
Head to the notebook for hands-on exploration of everything we've built!
What's next (Week 5)
Next week we connect our hybrid search to LLM generation for complete RAG:
Week 5 preview:
Ollama integration: Local LLM inference for answer generation
RAG pipeline: Query → Hybrid Search → Context Selection → LLM → Response
Citation system: Source attribution and evidence linking
Answer quality: Response validation and improvement strategies
The goal: Build search that understands both what users say (BM25) and what they mean (vectors), then generate answers that are accurate, cited, and contextually relevant.
Follow Along: This is Week 4 of 6 in our Zero to RAG series. Every Thursday, we release new content, code, and notebooks.
Let's go 💪
I am pretty deep into RAG and wanted to add that this is great stuff. I need to go back and start from the beginning. Also, I really like your style, great mix of detail and graphics, I need to adopt it! haha.
Thanks for the good 😊