

The Mother of AI project
A real world hands-on AI project series


Hey there 👋
We’re
and - two AI practitioners with 17+ years of combined experience building production-grade ML systems in the wild.Over the years, we’ve built RAG pipelines, AI Agents, Recommender systems, MLOps platforms, LLM-based agents, and everything in between. All in production!
Now, we’re opening that experience to the world - through a hands-on, open-source, no-hype learning initiative we call
The Mother of AI Project
This isn’t a typical AI course or bootcamp.
It’s a build-first, learn-by-doing, production-ready AI roadmap - made up of multiple focused phases, each guiding you through building a complete system from scratch.
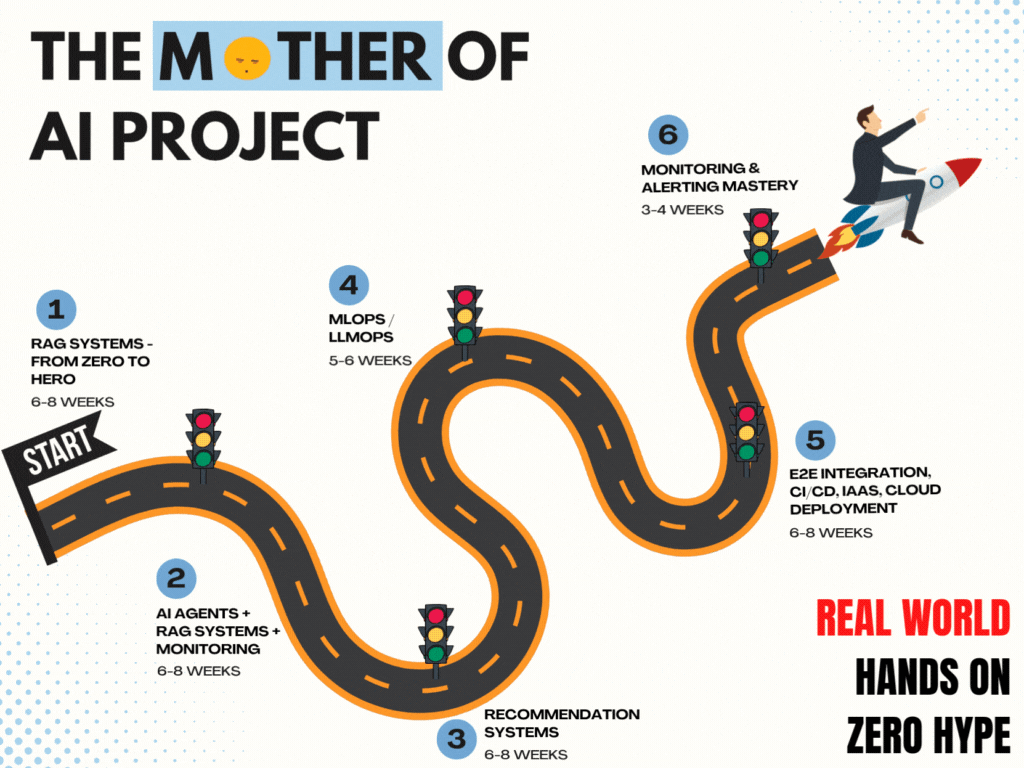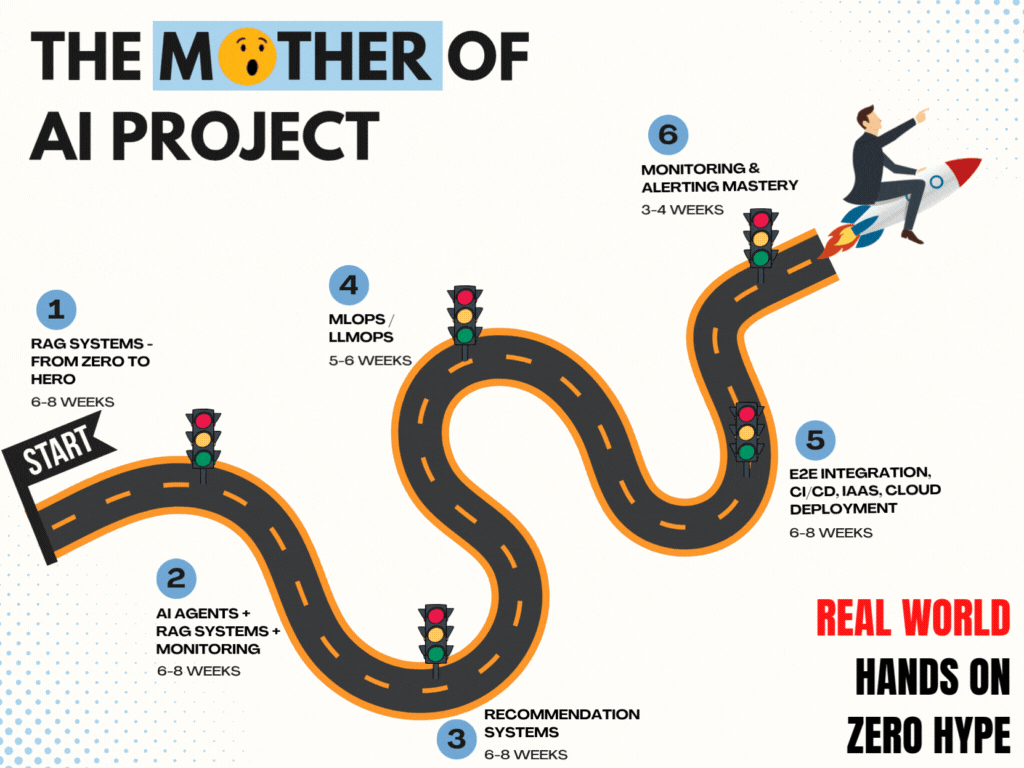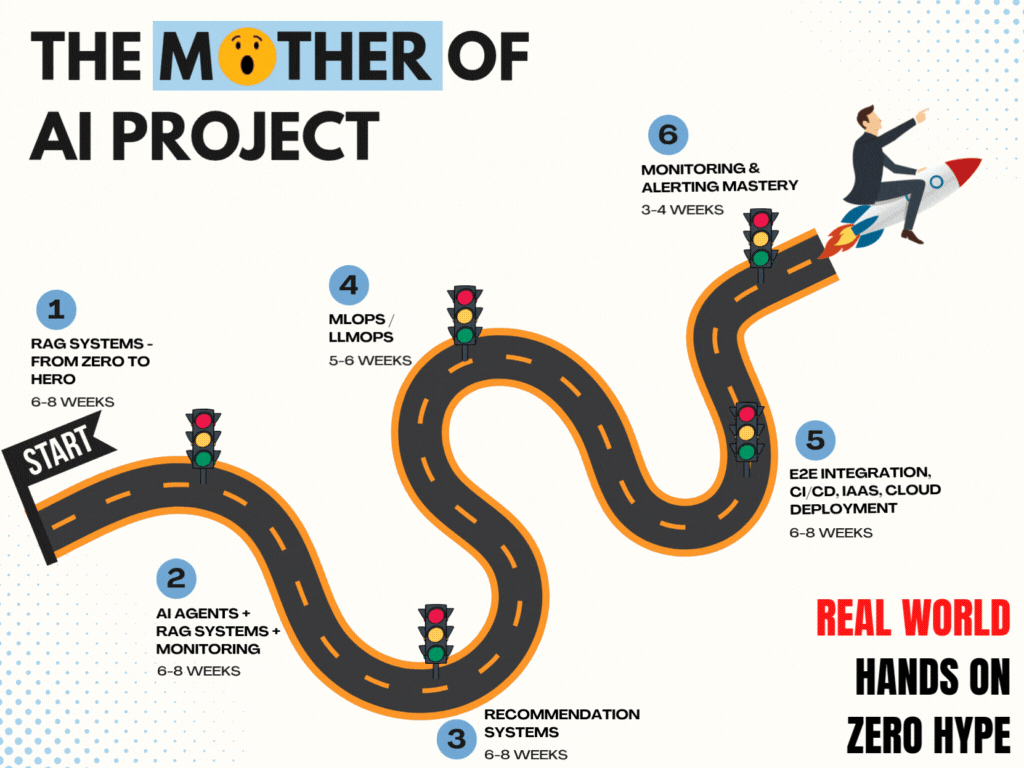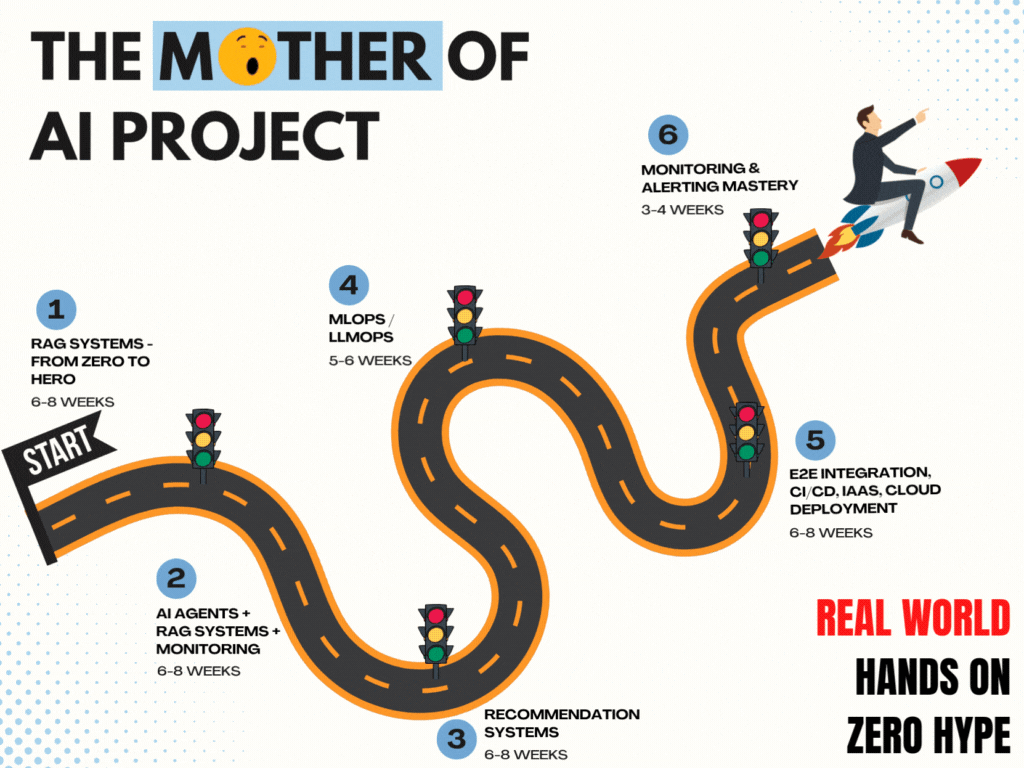
The Project Phases
Phase 1 – RAG Systems : Zero to Hero
Build a personalized AI research assistant from scratch
Ingest 1000+ research papers, chunk, embed, and run hybrid search + LLM-based RAG + Monitoring
(This is what we’re starting with - full details below)
Phase 2 – AI Agents + Tool Use + Monitoring (new project)
Move beyond static RAGs.
Build decision-making agents with memory, planning, and tool use.
Multi-step reasoning, better interactivity, and deeper retrieval.
Phase 3 – Recommendation Systems (new subproject)
Build real-time content-based or hybrid multi-stage recommender systems.
Cover ranking, user personalization, feedback loops, and metrics.
Phase 4 – MLOps + LLMOps (continued)
Take your models to production
Make use of the most popular Cloud services & pipelines here.
CI/CD, evaluation harnesses, fine-tuning, prompt versioning, data pipelines, security, and testing - Alles!
Phase 5 – Full App Integration + Cloud Deployment (continued)
From one of the most suitable project above!
Bring everything together.
Containerization, API orchestration, front-end demo, cloud deployment (AWS/GCP), CI/CD, IaaS, cost optimization, etc.
Phase 6 – Monitoring + Alerting Mastery (continued)
Build reliable systems that never go silent.
Logging, tracing, drift detection, alerts, and incident-ready dashboards.
Each phase isn’t a toy demo . it’s a production-grade system you’d be proud to showcase.
You’ll learn how to think and build like a real-world AI/ML engineer - using tools that teams actually use in production: Docker, FastAPI, Airflow, Ollama, LangGraph, OpenSearch, Langfuse, and many more.
(we only teach what’s truly useful and community-backed).
💼 Everything you build is CV-worthy!
We’ll not only walk you through best practices -
we’ll show you how to extend each system, adapt it for your own use case, and communicate it effectively on your resume or portfolio.
Who is this for?
If you’re tired of surface-level tutorials and want to go deeper - this is for you.
Whether you’re:
A student working toward your first real AI project
A Data Scientist looking to level up your software and infra skills
A Data/Backend/Software Engineer curious about LLMs, RAG, or Agents
A working AI/ML Engineer who wants to learn GenAI systems, for real
Anyone who is looking into entering this industry by learning great projects!
Pre-requisites: Good Python knowledge and understanding of software programming.
This will accelerate your path - with structure, hands-on examples, and mentorship from people who’ve built this in the wild.
Next: dive into Phase 1: RAG Systems (Zero → Hero)
Phase 1: Build Your Own AI Research Assistant
We’re kicking off the Mother of AI Project with what we believe is one of the most impactful AI skills right now:
RAG (Retrieval-Augmented Generation) - used in everything from chatbots to search, internal knowledge bases, agents, and assistants.
But we’re not stopping at “just” RAG.
You’ll build a complete research assistant that:
Runs automated data ingestion pipelines
Downloads and Parse 100+ academic PDFs (e.g. arXiv papers) through APIs
Search across papers with keywords and embeddings
Answer questions using local or foundational LLMs (Ollama, OpenAI, etc.)
Show sources, give feedback, and maintain privacy
A complete real production grade system!
This is what we call the ArXiv Paper Curator - an AI system that turns the flood of new AI research into structured, searchable knowledge.
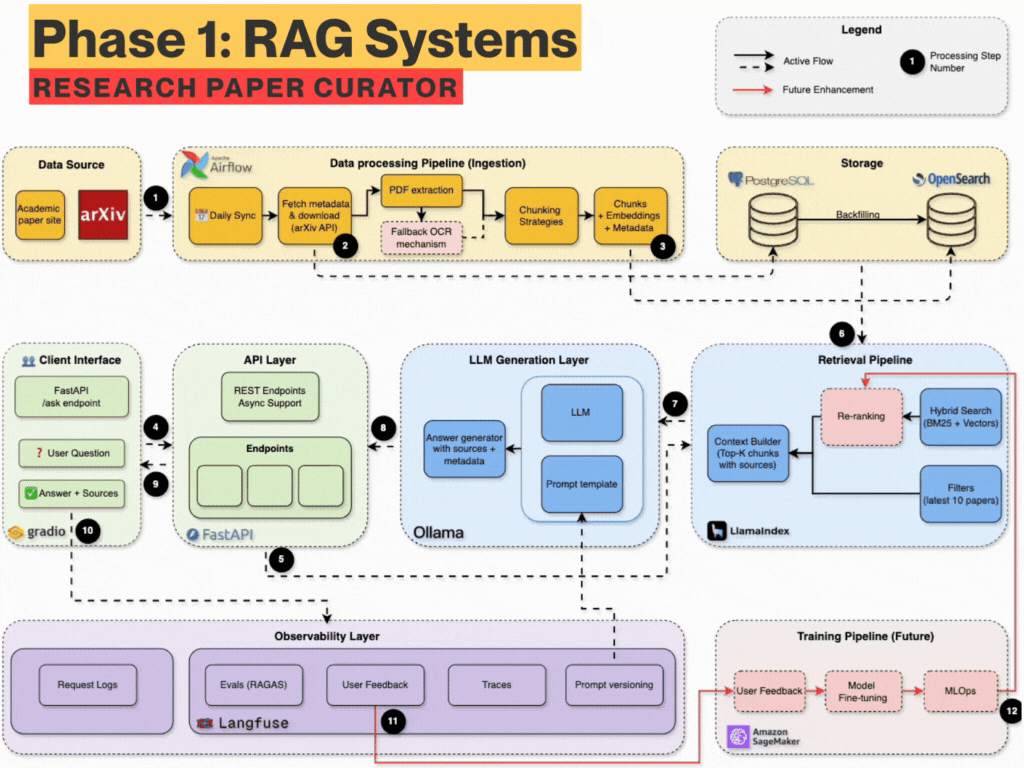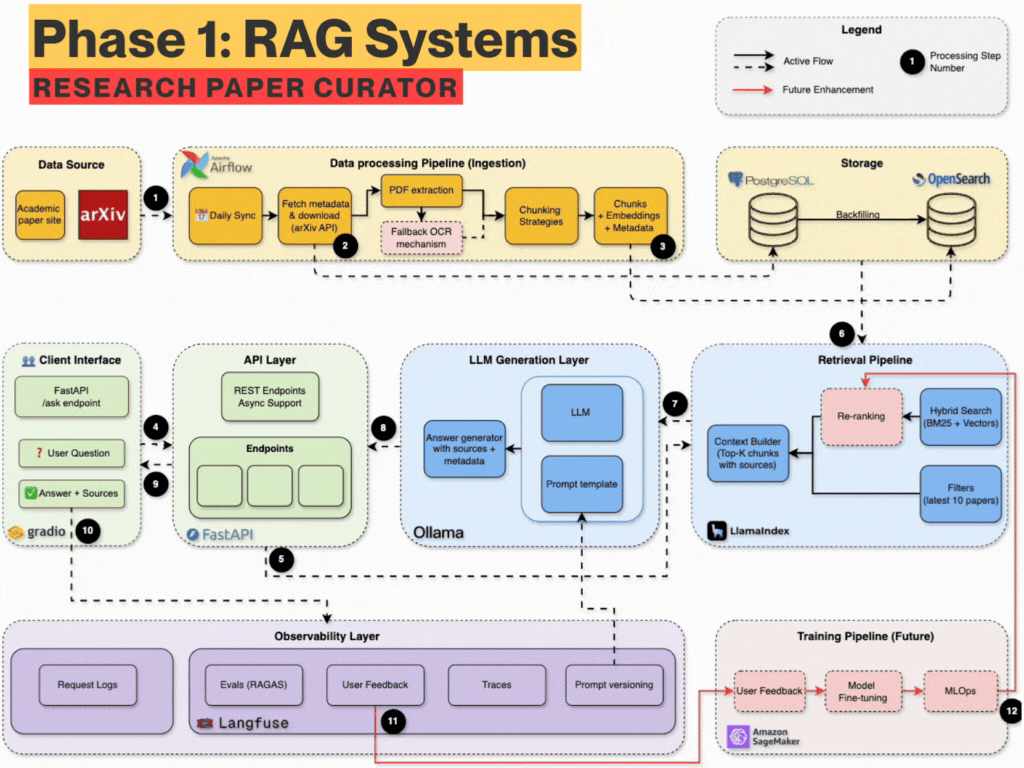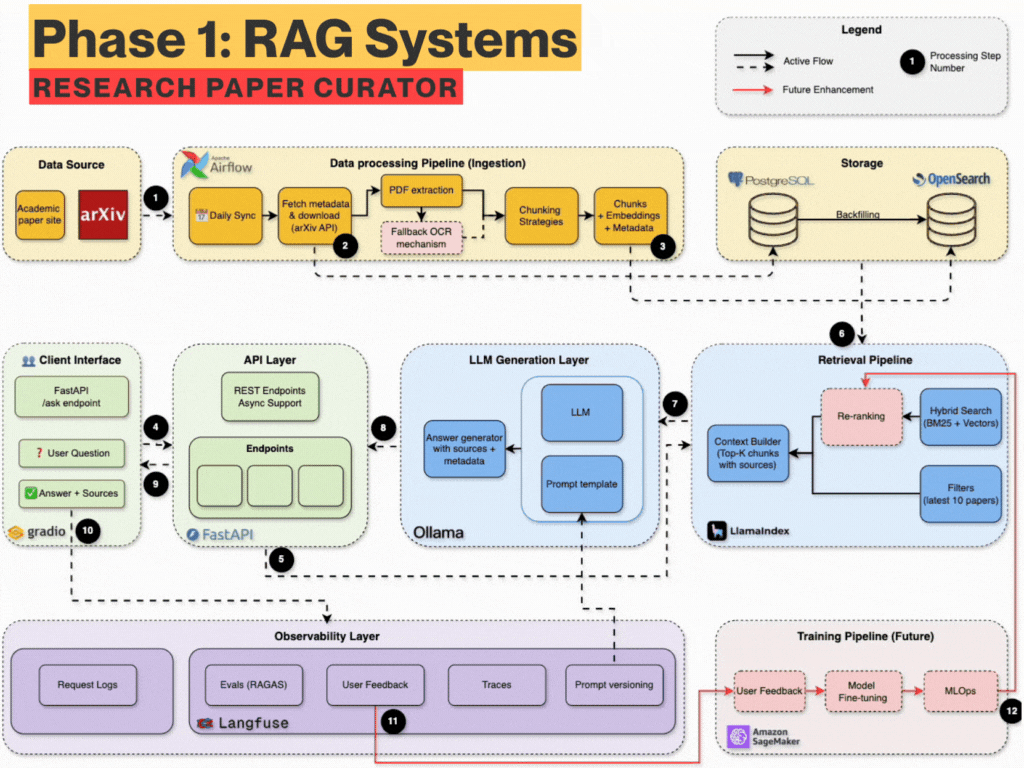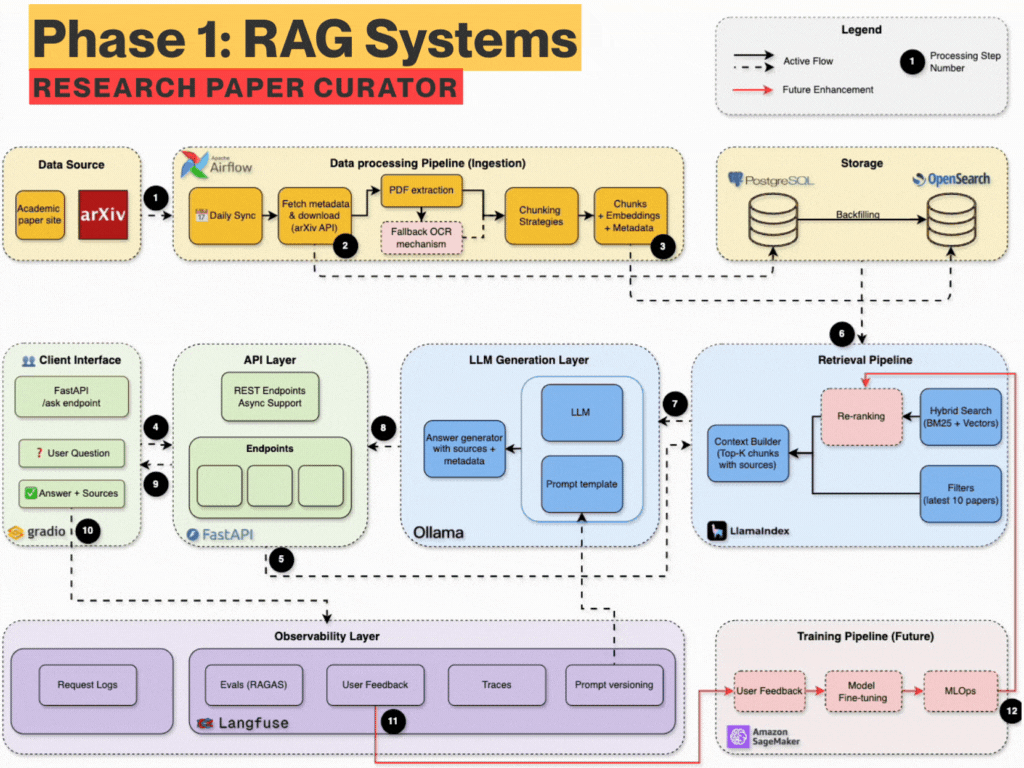
What you’ll build (Technical Breakdown)
You will build from scratch - a fully local with API integration, production-grade RAG system with:
Data Ingestion: Auto-download PDFs daily from arXiv using Airflow
Dual Parsing: Extract structured content via GROBID + Docling fallback
Metadata Storage: Store authors, titles, abstracts, etc. metadata in PostgreSQL
Search Engine: Use OpenSearch with BM25 + semantic vectors (hybrid)
Chunking Engine: Semantic-aware chunking (evaluate different chunking)
Embedding Store: SentenceTransformers + LlamaIndex indexing
RAG Pipeline: Query expansion + retrieval + prompt templating
Local LLM: Answer questions using Ollama or API (LLaMA3, OpenAI, etc.)
Observability: Use Langfuse for prompt versioning, tracing, quality
Evaluation: RAGAS metrics, nDCG scoring, accuracy, latency tracking
Frontend: Ask questions and explore results via Streamlit or Gradio
FastAPI Backend: Async API server for integration and extensions
Dev Best Practices: uv, ruff, pre-commit, pydantic, pytest, logging, etc.
📆 The 6-Week Learning Plan
You follow along, build that week’s part. Here’s the weekly breakdown:
Week 1: Infrastructure & API setup
What You'll Build:
FastAPI skeleton project setup
Complete Docker Compose stack orchestrating all services
FastAPI application with health checks and basic endpoints
PostgreSQL and OpenSearch containers with proper networking
Ollama container for local LLM inference
Mock data pipeline for testing without external dependencies
Key Learning Outcomes:
Understanding microservices architecture for AI applications
Setting up development environments with hot-reloading
Implementing async FastAPI endpoints with proper error handling
Container networking and service discovery
Environment configuration and secrets management
🔗 Code - https://github.com/jamwithai/arxiv-paper-curator
🔗 Blog -

Week 2: Ingestion pipeline
What You'll Build:
arXiv API client with rate limiting and retry logic
Automated metadata fetcher for academic papers
Parallel PDF downloader with progress tracking
GROBID integration for scientific PDF parsing
Docling fallback for robust document processing
Airflow DAGs for orchestrating daily ingestion
Key Learning Outcomes:
Working with external APIs respectfully (rate limiting)
Handling large file downloads efficiently
Implementing fallback patterns for reliability
Understanding PDF parsing challenges in academic documents
Building fault-tolerant data pipelines
Async/await patterns for I/O operations
🔗 Code - https://github.com/jamwithai/arxiv-paper-curator
🔗 Blog -

🔍 Week 3: Search infrastructure
What You'll Build:
OpenSearch mapping optimized for academic content
PostgreSQL schema with JSONB for flexible metadata
Dual-storage strategy implementation
Custom analyzers for scientific terminology
Multi-field search with BM25 scoring
Category, author, and date range filtering
Search result ranking and relevance tuning - e.g. latest papers.
Key Learning Outcomes:
Designing schemas for dual-storage systems
OpenSearch analyzers and tokenizers for academic text
Building complex search queries programmatically
Understanding BM25 and relevance scoring
Implementing faceted search and filters
Performance optimization for search operations
Filters, date range, and relevance scoring
🔗 Code - https://github.com/jamwithai/arxiv-paper-curator
🔗 Blog -

Week 4: Chunking + retrieval evaluation
What You'll Build:
Context-aware chunking that preserves paper structure
Chunk size optimization based on retrieval performance
nDCG, precision, and recall metrics implementation
Query expansion for better recall
Key Learning Outcomes:
Why naive chunking fails for academic documents
Preserving semantic boundaries in technical text
Implementing evaluation metrics for retrieval systems
Testing different chunking strategies
Understanding the precision-recall tradeoff
Query expansion techniques that work
🔗 Code - https://github.com/jamwithai/arxiv-paper-curator
🔗 Blog -

Week 5: Full RAG system + prompts
What You'll Build:
End-to-end question answering system
LlamaIndex integration for RAG orchestration
Source tracking with paragraph-level citations
Prompt templates optimized for academic content
Context window management for long papers
Truncation strategies that preserve meaning
Answer generation with confidence scores
Key Learning Outcomes:
Implementing production RAG pipelines
Prompt engineering for factual accuracy
Managing context windows effectively
Handling multi-document synthesis
Building citation systems users trust
Balancing comprehensiveness with conciseness
🔗 Code - https://github.com/jamwithai/arxiv-paper-curator
🔗 Blog -

Week 6: Observability + versioning
What You'll Build:
Langfuse integration for complete observability
Prompt versioning and A/B testing framework
Performance monitoring dashboards
Request tracing from question to answer
Gradio interface for easy interaction
Caching layer for common queries
Production deployment configurations
Key Learning Outcomes:
Implementing observability for LLM applications
Data-driven prompt optimization
Building intuitive research interfaces
Performance profiling and optimization
Caching strategies for AI systems
Production deployment best practices
🔗 Code - https://github.com/jamwithai/arxiv-paper-curator
🔗 Blog -

What to do now?
✅ Subscribe to
for weekly updates✅ Bookmark this blog - we update links as the weeks go
✅ Get your hands dirty - every week’s notebook will be ready to run
The future of AI systems is being built - you should be building them too.
Let’s go 💪
Hi. When will Phase 2 start?
When is the next cohort ? Please let us know